циклевание без пыли и покрытие лаком старого паркета , как отциклевать старый паркет, шлифовка своими руками
Паркет – напольное покрытие популярное во все времена. Материал ассоциируется с теплом и уютом домашнего очага, классическим благородным стилем.
Несмотря на свою износостойкость и долговечность, дерево нуждается в периодически осуществляемой реставрации. Операция необходима, поскольку любое напольное покрытие в процессе эксплуатации тускнеет, царапается, вышаркивается. Для этих целей была разработана техника циклевания паркета.
Что такое циклевка паркета?
Процесс циклевки паркета представляет собой снятие с его поверхности тонкого верхнего слоя с помощью специального оборудования. Операция позволяет вернуть полу гладкость, устранить дефекты в виде царапин, сколов и вмятин, устранить скрип половиц.
Операция позволяет вернуть полу гладкость, устранить дефекты в виде царапин, сколов и вмятин, устранить скрип половиц.
Цикля – название шлифовальной машинки, которое было использовано для наименования самого процесса.
Виды циклевки
Циклевание можно производить несколькими способами.
Ручной
Метод был распространен до появления механических приспособлений. Он требует от мастера больших усилий и времени. Ручная цикля представляет собой заточенную металлическую пластину, загнутую под углом 45 градусов к рукоятке. Она имеет разные формы. Как правило, используют инструмент шириной около 5 см.
Шлифовка может быть выполнена и с помощью крупнозернистой наждачной бумаги.
Но данный вид работ настолько утомительный, что на больших площадях не рекомендован.
 Но данный вид работ настолько утомительный, что на больших площадях не рекомендован.
Но данный вид работ настолько утомительный, что на больших площадях не рекомендован.Полуавтоматический
В данном случае применяются различные приспособления для ручных инструментов. Например, циклевание болгаркой. Для этого на ее диск подклеивают наждачку. Кроме того используют ленточные и ротор-орбитальные шлифовальные машины.
Механический
Способ появился в 70-х годах с разработкой специальной машины, оснащенной ножами. С их помощью срезался верхний слой напольного покрытия толщиной до 16 мм. В связи с появлением нового шлифовального оборудования процесс стал бережнее, качественнее, менее вредным для паркета. Для механической циклевки без пыли лучше пользоваться аппаратом с встроенным пылесборником.
Особенности работ с разными видами паркета
Шлифовка паркетного пола производится в следующих случаях:
- Новая сборка шпунтованных планок перед последующим оформлением. Циклевание нового паркетного покрытия проделывают в два этапа. Первый проводят по слегка влажному полу, вторым осуществляется финишная зачистка сухой поверхности.
- Реставрация старого пола. К операции стоит прибегать, если пол сильно затоптан и исцарапан, паркет покрыт пятнами, лак облупился и потускнел, половицы начали скрипеть.
 Циклевание нового паркетного покрытия проделывают в два этапа. Первый проводят по слегка влажному полу, вторым осуществляется финишная зачистка сухой поверхности.
Циклевание нового паркетного покрытия проделывают в два этапа. Первый проводят по слегка влажному полу, вторым осуществляется финишная зачистка сухой поверхности.
Отличие процесса циклевки старого и нового паркета в том, что в первом случае снимается минимальный слой древесины, поскольку он не обременен лаком, пятнами и царапинами.
Циклевку производить не целесообразно при наличии факторов, выделенных ниже:
- Зазоры между планками больше 5 мм заделывать нет необходимости, нужно полностью менять указанный участок напольного покрытия. В противном случае к нему придется вернуться в дальнейшем. При наличии сильных повреждений, образованных в результате разных факторов. К ним относятся:
 В противном случае к нему придется вернуться в дальнейшем. При наличии сильных повреждений, образованных в результате разных факторов. К ним относятся:
В противном случае к нему придется вернуться в дальнейшем. При наличии сильных повреждений, образованных в результате разных факторов. К ним относятся:
- Перепад высот, что вызывает искривление планок. В результате половицы вытираются при трении друг о друга.
- Порча древесины древоточцами. Дефект можно определить с помощью обычного шила. Если оно без усилия под углом входит в тело пластины, значит древесина испорченная.
- Глубокие царапины и трещины.
- Циклевка производилась несколько раз. Толщина паркета не позволяет осуществлять реставрацию бесконечное число раз. Разрешается максимум 3 раза.
- Затопление пола водой, что вызвало появление плесени и грибка. Здесь придется полностью менять покрытие. Чтобы проверить влажность пола, нужно застелить отдельный участок полиэтиленом, плотно прикрепив его к полу. Температура в помещении должна быть в пределах 20-25 градусов. Если по истечении суток на пленке появился конденсат, значит дерево мокрое. Лучше демонтировать его или грамотно организовать гидроизоляцию.
 Если по истечении суток на пленке появился конденсат, значит дерево мокрое. Лучше демонтировать его или грамотно организовать гидроизоляцию.
Если по истечении суток на пленке появился конденсат, значит дерево мокрое. Лучше демонтировать его или грамотно организовать гидроизоляцию.
Циклевка зависит от материала паркета. Твердые породы дерева потребуют существенных усилий, тогда как мягкие легки для обработки.
Тонкости обработки дубового покрытия
Элитный дубовый паркет отличается определенной жесткостью древесины, соответственно при обработке будет оказывать максимальное сопротивление.
Для качественной шлифовки лучше выбрать циклевочную машину барабанного типа с насадкой из специального прочного материала. Выравнивание дубового паркета требует самого грубого крупнозернистого абразивного материала.
Выравнивание дубового паркета требует самого грубого крупнозернистого абразивного материала.
При тонировке и лакировании следует помнить следующее:
- Древесина дуба со временем изменяет свой цвет, это называется морением. В связи с этим старый паркет имеет почти черный цвет.
- Дерево имеет большую плотность, соответственно, обладает низкой степенью впитывания красящих веществ. В результате имеет блеклый цвет.
Щитовой паркет, в отличие от штучного, состоит из модулей в виде щитов, на которые наклеены плашки. Благодаря такой структуре, на укладку покрытия затрачивается меньше сил и времени.
Циклевать щитовое деревянное покрытие можно только 2 раза, поскольку верхний слой достаточно тонкий.
При работе с щитовым паркетом заранее определяют толщину полезного слоя, то есть расстояние от наружного слоя до замкового шпунта. Как правило, оно может меняться в пределах 2-6 мм. Соответственно, чем больше толщина, тем крупнее гранулы абразивного материала можно использовать.
Как правило, перед циклевкой рекомендуют всю мебель вынести. Однако в комнате могут быть установлены крупногабаритные тяжелые предметы, которые не сдвигаются. Поэтому старый паркет циклюют по их периметру.
Этапы работы
Перед началом работы необходимо ознакомиться с рекомендациями специалистов, разработать для себя инструкцию к действию, подготовить инструменты и помещение.
Инструменты
Вам потребуется шлифовальный аппарат или цикля бывает ручной и автоматической. Второй вариант очень дорого стоит, поэтому для ремонта квартиры или частного дома лучше взять его в аренду. Виброшлифовальные машинки, которые используются для ручной обработки, гораздо дешевле, чем автоматическое оборудование. Однако они не могут обеспечить хорошую степень гладкости. Ручная цикля может пригодиться для шлифовки полов в углах помещения и вокруг крупногабаритной мебели.
Станок для шлифовки барабанного или ленточного типа значительно увеличивает скорость реставрационных работ. Профессионалы отмечают, что подобное оборудование лучше применять для реставрации поверхностей большой площади. Ленточный паркетношлифовальный аппарат, оборудованный барабаном, выпускается в двух вариантах: с однофазным или трехфазным приводом. Модели в большинстве случаев оборудованы пылесборником. Отмечают недостаток в виде неравномерности шлифования, поэтому рекомендуют использовать только для грубой циклевки.
Ленточный паркетношлифовальный аппарат, оборудованный барабаном, выпускается в двух вариантах: с однофазным или трехфазным приводом. Модели в большинстве случаев оборудованы пылесборником. Отмечают недостаток в виде неравномерности шлифования, поэтому рекомендуют использовать только для грубой циклевки.
Дисковая плоскошлифовальная техника – одна из последних разработок, поэтому лишена недостатков, присущих предшественникам. Машина с дисковыми насадками используется для тонкого выравнивания пола, а также для шлифовки слоев при лакировке.
Среди других инструментов необходимы:
- Угловые машины типа «сапожок» применимы для обработки труднодоступных мест в помещении: в углах, под отопительными приборами, вокруг массивной мебели или вдоль плинтуса. Современные модели снабжены мешками для мусора.
- Строительный пылесос используется в основном в промышленных целях, для домашнего использования покупать его нецелесообразно. Лучше взять в аренду или воспользоваться веником и обычным бытовым пылесосом.
- Насадки для циклевочной машины.
- Болгарка, дрель.
- Шуруповерт.
- Гвозди, шурупы.
 Современные модели снабжены мешками для мусора.
Современные модели снабжены мешками для мусора.
Материалы
Вам потребуется:
- Дополнительные паркетные планки для замены испорченных.
- Наждачная бумага разной степени зернистости. Для циклевки ее нужно очень много, поэтому запас должен быть существенным.
- Шпатлевка по дереву в готовом виде. Подойдет состав либо на водной основе, либо на нитрорастворителе. Специалисты иногда самостоятельно замешивают раствор из древесной пыли, которая остается при шлифовании.
- Шпатели для укладки шпатлевки.
 Подойдет состав либо на водной основе, либо на нитрорастворителе. Специалисты иногда самостоятельно замешивают раствор из древесной пыли, которая остается при шлифовании.
Подойдет состав либо на водной основе, либо на нитрорастворителе. Специалисты иногда самостоятельно замешивают раствор из древесной пыли, которая остается при шлифовании.
- Грунтовка для дерева.
- Кисти и валики для нанесения грунтовки.
- Средства индивидуальной защиты: перчатки, респиратор или марлевая повязка, очки.
- Напольные защитные средства: воск, масло, антигрибковые составы.
- Декоративные покрытия: тонировка, морилка, лак.
Подготовка помещения
Непосредственно перед работой нужно осуществить вынос мебели из помещения. Если какие-то предметы не сдвигаются, то можно оставить их на месте, но предварительно закрыть чехлами. Циклевание – процесс очень грязный, пыль будет лететь во все стороны.
Если какие-то предметы не сдвигаются, то можно оставить их на месте, но предварительно закрыть чехлами. Циклевание – процесс очень грязный, пыль будет лететь во все стороны.
Плинтус снимается по всему периметру. Иногда его оставляют, но только в случае, когда безболезненно демонтировать не получается. Пол следует сначала помыть, а затем почистить. В результате покрытие должно избавиться от пыли, грязи и мелкого мусора.
Помещение рекомендуется обезопасить, для чего все лежащие провода необходимо спрятать в специальные коробы для коммуникаций или с помощью изоленты поднять их с пола. Если паркет в удовлетворительном состоянии, то подготовка практически закончена. Достаточно углубить шляпки гвоздей, чтобы не повредить шлифовальную машину.
В противном случае придется сначала устранить дефекты пола в виде выпадающих планок, глубоких царапин.

Виды дефектов и их устранение
Выделяют:
- Провалы отдельных планок в паркете. Требуется вынуть поврежденную пластину, зачистить образовавшееся углубление и уложить в него новую плашку, фиксируя ее клеем.
- Плохо закрепленные паркетные пластины следует зафиксировать либо гвоздями, либо с помощью клея. Шляпку углубить в древесину не меньше, чем на 2 мм. Если планки крепились скрытым способом, то целесообразнее воспользоваться клеем.
- Скрип деревянных полов возникает вследствие усыхания и старения древесины. В этом случае скрипящие половицы укрепляются по углам тонкими гвоздями. Можно применять другой способ: между паркетными пластинами вбивают деревянный штифт, покрытый клеем.
- Глубокие щели, если их немного, можно заполнить тонкими деревянными пластинками, смазанными клеем со все сторон. После просушки материала верх подрезается вровень с поверхностью пола рубанком.
- Крупные множественные трещины и отверстия шпаклевать по отдельности нецелесообразно. Лучше заменить совсем.
 После просушки материала верх подрезается вровень с поверхностью пола рубанком.
После просушки материала верх подрезается вровень с поверхностью пола рубанком.
Технология циклевки своими руками
Отциклевать паркет можно вручную или с использованием механических средств.
Ручная циклевка
Ручную циклю необходимо вести вдоль древесных волокон с небольшим нажимом в сторону движения под углом 45 градусов. Чтобы тратить меньше усилий, древесину заранее увлажняют, а инструмент периодически затачивают. Самый главный плюс метода – он беспыльный.
Машинный процесс
Технологии значительно изменились, теперь восстановление полов в домашних условиях – менее трудоемкий, быстрый, и качественный процесс. С помощью технических средств реставрация осуществляется самостоятельно. Начинать циклевать нужно только после того, как машинка набрала обороты. Если опустить аппарат на пол раньше, то получится вмятина.
С помощью технических средств реставрация осуществляется самостоятельно. Начинать циклевать нужно только после того, как машинка набрала обороты. Если опустить аппарат на пол раньше, то получится вмятина.
Грубая циклевка завершается, если поверхность приобрела характерный древесный оттенок.
Этапы работ
Первая циклевка. Главная задача – выровнять паркет и удалить слой старого лака. Указанный этап называют «грубая шлифовка», поскольку в процессе снимается самый большой древесный пласт, чтобы удалить неровности и въевшуюся грязь. Как итог, паркетный пол становится ярче. Специалисты рекомендуют производить интенсивную обработку глубиной до 5 мм. Наждачный элемент для грубой очистки выбирают крупно абразивный (Р40).
Как правило, первую циклевку проводят по диагонали, пользуясь машиной барабанного типа или дисковой плоскошлифовальной.
При узорчатой укладке паркета есть свои особенности обработки:
- «елочка», направление движения диагональное.
- «плетенка» и «дворцовый», циклевание производится крест-накрест.
- «художественный наборный», движение по спирали от центра комнаты.
При работе с машиной следует совершать плавные движения с постоянной скоростью. Если работник остановится или задержится на одном месте, то появится углубление.
Второе циклевание или шлифовка проводится после уборки мусора, который образовался при осуществлении предыдущего этапа. Места, в которые трудно добраться циклевочным аппаратом, и углы в помещении обрабатываются ручной циклей или с помощью специальных машинок типа «сапожок». В домашних условиях можно воспользоваться болгаркой со шлифовальной насадкой.
Третья циклевка доводит процесс шлифования до логического конца, устраняя недостатки, с которыми не справился обычный шлифовальный аппарат. Ее проводят в перпендикулярном направлении к движению циклевочного аппарата на первом этапе.
Ее проводят в перпендикулярном направлении к движению циклевочного аппарата на первом этапе.
На этапе ремонта обрабатывают щели шпаклевочными пастами. Для устранения сколов и трещин осуществляют подбор коррекционных составов, индивидуальных для каждого отдельного случая, с учетом структуры и цвета древесины. Приступать к следующему этапу следует только после полного высыхания шпаклевки. Кроме готовых составов используют пасту, приготовленную из древесной пыли, образовавшейся при циклевке, и клея ПВА.
Финишное циклевание призвано сделать паркет ровным, обновить поверхность. Для чего плоскошлифовальным аппаратом снимается тонкий верхний слой, чтобы убрать излишки пасты. Операция выполняется только вдоль паркетных пластин.
Завершающий этап
После циклевки следует подмести крупный мусор и пылесосом ликвидировать мелкий. В качестве защиты паркет покрывают антисептиком или огнебиозащитным средством.
В качестве защиты паркет покрывают антисептиком или огнебиозащитным средством.
Чтобы придать отреставрированной поверхности идеальный внешний вид, предварительно осуществляется ее тонировка или покраска. Самому правильно покрасить паркет несложно, но лучше заранее ознакомиться с рекомендациями специалистов.
После тонировки поверхность грунтуется в два слоя и шлифуется мелкой наждачкой. Грунтовка исправит оставшиеся недочеты. После этого специалисты рекомендуют делать технологический перерыв в 2-3 дня, что даст возможность поверхности полностью высохнуть и полимеризоваться.
Лакировка – заключительный этап
При выборе лака следует ориентироваться на функциональную специфику помещения и тип древесины.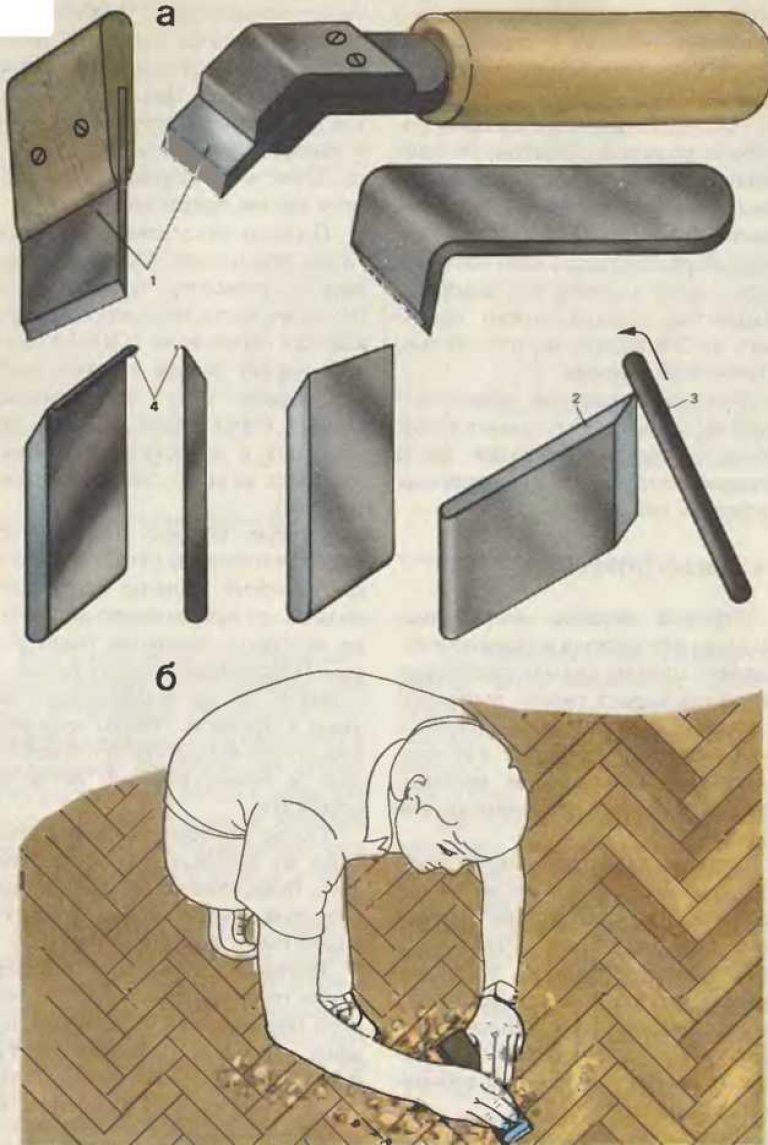 Наносить его рекомендуют с самого освещенного места. Покрытие паркета лаком в несколько слоев значительно увеличит срок эксплуатации. Для обеспечения хорошей адгезии между слоями, каждый из них следует шлифовать.
Наносить его рекомендуют с самого освещенного места. Покрытие паркета лаком в несколько слоев значительно увеличит срок эксплуатации. Для обеспечения хорошей адгезии между слоями, каждый из них следует шлифовать.
Лакокрасочные средства классифицируются следующим образом:
- С обратимыми пленками (высыхающими). Класс включает битумные, нитроцеллюлозные и шеллачные лаки. За основу в битумных или «асфальтовых» составах берут природные или нефтяные битумы, поскольку они обладают высокой устойчивостью к влаге. Правда, нужно отметить их быстрое загустение. Нитролаки производят из нитрата целлюлозы. Они быстро сохнут, но обладают низкой водоустойчивостью.
- С защитной необратимой твердеющей пленкой. В группу попадают алкидные, мелалиноалкидные, эпоксидные, полиуретановые лаки.
Лак рекомендуют наносить на паркет кистью, двигаясь вдоль древесных волокон.
 Для первого слоя состав должен быть жидким, чтобы обеспечить хорошую впитываемость.
Для первого слоя состав должен быть жидким, чтобы обеспечить хорошую впитываемость.Натирка паркета
Можно завершить реставрацию напольного покрытия не лакированием, а натиркой паркета специальными мастиками. Готовые составы продают в строительных магазинах. На упаковке производители указывают состав, способ нанесения и расход материала. При натирке паркетных полов следует учитывать породу древесины. Березовые и буковые плашки разбухают от влаги, поэтому им противопоказаны мастики на водной основе, лучше на скипидаре.
Чаще пользуются растворами с воском, которые перед перемешиванием разбавляются кипятком. Для нанесения смеси на паркет тонким слоем используют щетку или широкую плоскую кисть. Когда первый слой подсохнет, пол покрывают мастикой во второй раз. В конце процедуры паркет натирают полотерной щеткой или специальной машинкой.
Современный рынок предлагает кроме мастик специальные смеси, в состав которых входят природные смолы или пчелиный воск, а также натуральные масла. Они замечательно подходят не только в защитных, но и в декоративных целях, поскольку хорошо проникают внутрь древесины и обрисовывают ее текстуру.
Они замечательно подходят не только в защитных, но и в декоративных целях, поскольку хорошо проникают внутрь древесины и обрисовывают ее текстуру.
Паркет становится выразительнее, интереснее, одновременно он защищен от истирания. Например, «УФ масло» позволяет обновлять состав один раз в несколько лет.
Мастика – материал ненадежный с низкой степенью устойчивости. Она истирается за короткое время, и операцию придется повторять снова. Поэтому в защитных целях лучше использовать лак.
Советы и отзывы
Реставрировать паркетный пол следует, как минимум, раз в пять лет. Перед циклеванием следует протереть пол мокрой тряпкой, это смягчит дерево. Процедура обработки проводится при соблюдении температурного режима. В холодный период циклевать рекомендуется при включенном отоплении и закрытых окнах.
В холодный период циклевать рекомендуется при включенном отоплении и закрытых окнах.
Работая с паркетом, следует надевать мягкие носки, поскольку даже очень мягкая обувь наносит вред незащищенному покрытию. При использовании циклевочной машинки не должно быть длинных одежд, чтобы избежать затягивания их деталей внутрь аппарата. Можно циклевать паркет только в респираторе и за закрытыми дверьми. Работа сопровождается большим количеством пыли, поэтому рекомендуется предотвратить возможность ее распространения в другие комнаты и постараться избежать проникновения в дыхательные пути.
Если есть возможность обновить паркет без циклевания, то стоит ею воспользоваться.
При использовании оборудования в домашних условиях следует заранее убедиться, что электрическая проводка способна выдержать дополнительную нагрузку. Начинать процедуру обработки следует из центра комнаты. При движении каждая следующая полоса должна находить на предыдущую.
При движении каждая следующая полоса должна находить на предыдущую.
Не следует сильно давить на циклевочную машину, поскольку она оставляет вмятины, которые будет сложно устранить. Шлифовку производят вдоль древесных волокон, чтобы не нарушать структуру. Для безупречной циклевки паркета из древесины твердых пород подходит барабанный аппарат. Однако обработка им мягкой древесины может вызвать появление волнообразных дефектов поверхности. Поэтому первичная циклевка во втором случае осуществляется ленточными машинами.
При использовании шпатлевки по дереву следует помнить, что она не сочетается с твердыми древесными породами. Ее применение может вызвать пятна после нанесения лака на поверхность пола. Перед тем, как приступить к лакировке паркета, лак должен выстояться при комнатной температуре. Разница между светлыми и темными пластинами делает паркет более ярким и интересным, но если хочется сделать цвет более ровным, то его нужно либо тонировать, либо замаскировать матовым лаком.
Разница между светлыми и темными пластинами делает паркет более ярким и интересным, но если хочется сделать цвет более ровным, то его нужно либо тонировать, либо замаскировать матовым лаком.
Алкидный лак быстро сохнет, его срок службы составляет 10 лет. Паркет, покрытый эпоксидным лаком, выдержит до 30 лет, но покрытие сохнет в течение недели и является токсичным. Самый безопасный – акриловый вариант, он обеспечивает срок эксплуатации до 50 лет. Однако он весьма дорогой и имеет способность выгорать на солнце.
Если вы планируете также клеить обои, то работы по обработке пола лучше сделать раньше. На самом деле все зависит от профессионального уровня специалиста и современности техники. Если циклевку производит опытный человек, да еще с использованием современного высокотехнологичного оборудования, оснащенного пылесборниками, то реставрация паркета сильно не повлияет на окружающую обстановку.
В домашних условиях при циклевке своими руками может получиться много пыли и грязи, которые осядут на отремонтированных стенах. Как известно, не все типы обоев легко очищаются.
Для того, чтобы продлить срок эксплуатации паркета нужно следовать следующим правилам:
- Установить оптимальный уровень влажности в помещении.
- Устранить крупную абразивную грязь в виде песка и щебня, которая заносится с улицы. Для этого достаточно постелить перед входом коврик.
- Ультрафилетовая защита.
- Установка войлочных или резиновых мягких заглушек на ножки мебели.
- Регулярная ручная влажная уборка.
- Периодическая обработка специальными средствами – полиролью, воском или маслом.
О том, как циклевать паркет, смотрите в следующем видео.
 youtube.com/embed/bRgTW5cISmQ?modestbranding=1&iv_load_policy=3&rel=0″/>
youtube.com/embed/bRgTW5cISmQ?modestbranding=1&iv_load_policy=3&rel=0″/>
Циклевка паркета своими руками, или как не совершить ошибок + Видео
Если вы решили занять восстановлением, монтажом или ремонтом деревянного пола, то рано или поздно вам придется столкнуться с такими серьезными процессами, как циклёвка и последующая профессиональная шлифовка паркета: своими руками ее провести или отдать все же предпочтение мастерам – решать вам.
Циклевка паркета своими руками – учимся правилам монтажа паркетной доски
Как утверждают народные умельцы, многие монтажные работы по установке паркетной доски можно сделать вручную самому. Но, конечно же, без помощи техники здесь не обойтись. Так, для облегчения труда вы можете воспользоваться шлифовальной техникой. Она специально приспособлена для работы с паркетом. Впрочем, покупать такое дорогостоящее и профессиональное оборудование вам не стоит – подобная машинка вам обойдется в цену, равную цене половины легкового автомобиля среднего сегмента. А значит, вам понадобится просто взять шлифовальную машину в аренду – это будет дешевле, да и согласитесь, что, не будучи строителем, с таким процессом, как самостоятельно проведенная циклевка паркета, вы явно не будете сталкиваться ежедневно.
А значит, вам понадобится просто взять шлифовальную машину в аренду – это будет дешевле, да и согласитесь, что, не будучи строителем, с таким процессом, как самостоятельно проведенная циклевка паркета, вы явно не будете сталкиваться ежедневно.
Циклевание паркета своими руками предусматривает процесс шлифования наждачной бумагой. Речь идет сначала о выравнивании, снятии верхнего слоя дерева, а уж затем нанесении лакового покрытия. Ведь не секрет, что на старом паркете со временем образуются всяческие повреждения, различные царапины и остаются участки нанесенного годами ранее лакового покрытия. Но не следует спешить и сразу же приступать к работам. Лучше узнайте, как правильно циклевать паркет своими руками. Все дело в том, что к различным породам дерева должны применяться и разные режимы циклевки. Ведь мягкие и твердые породы древесины изначально имеют свойства, отличные друг от друга.
Кроме того, советуем подготовиться основательно – циклевка паркета в старой квартире может производиться несколько раз. Если паркетная доска у вас в совсем запущенном состоянии, то вам придется проходить циклевкой пол по 5 или более раз. Все будет зависеть от толщины поврежденного слоя. Его-то и нужно будет вам снять при помощи техники. Некоторые умельцы пытаются циклевать вручную, используя куски стекол или заточенные предметы, такие как нож. В принципе это возможно сделать и специальным устройством, состоящим из деревянной ручки и стальной острой пластины. Но это очень трудоемкая и сложная операция, которая потребует не только много сил, но и времени. Ведь на то, чтобы только один раз пройти ваш паркет в одной только комнате, уйдет не менее суток.
Если паркетная доска у вас в совсем запущенном состоянии, то вам придется проходить циклевкой пол по 5 или более раз. Все будет зависеть от толщины поврежденного слоя. Его-то и нужно будет вам снять при помощи техники. Некоторые умельцы пытаются циклевать вручную, используя куски стекол или заточенные предметы, такие как нож. В принципе это возможно сделать и специальным устройством, состоящим из деревянной ручки и стальной острой пластины. Но это очень трудоемкая и сложная операция, которая потребует не только много сил, но и времени. Ведь на то, чтобы только один раз пройти ваш паркет в одной только комнате, уйдет не менее суток.
Как циклевать паркет своими руками, или справляемся без труда со сложным заданием
Если ваш паркет циклюется вручную, то его предварительно нужно обязательно намочить влажной, неворсистой тряпкой. Как показывает практика, так работать легче. А уже за циклевкой следует следующий процесс – шлифовка. Но в любом случае пол перед обработкой и между циклами должен быть тщательно убран и помыт. Пыль желательно убирать несколько раз. Использовать для этой цели следует мощный пылесос.
А уже за циклевкой следует следующий процесс – шлифовка. Но в любом случае пол перед обработкой и между циклами должен быть тщательно убран и помыт. Пыль желательно убирать несколько раз. Использовать для этой цели следует мощный пылесос.
Если, шлифуя, вы удаляете крупные трещины, царапины и щели, то циклюя – снимаете верхний слой и мелкие шероховатости. В любом случае, эти два процесса отвечают еще и за процесс выравнивания пола. Если этот пункт не будет соблюдаться, то вы рискуете в дальнейшем столкнуться с видимыми «перепадами» пола и внешней «корявостью». Все прорехи будут особо видны после нанесения и высыхания лака. На помощь может прийти и всем известная наждачная бумага. Впрочем, тогда вам придется запастись еще большим терпением и старанием. Эта работа и пыльная, и трудоемкая.
Тем, кто любит советы «самоделкиных», предлагаем следующее – учитывая то, что ноги у многих людей сильнее, чем руки, можно наждачную бумагу приклеить к подошве резиновым клеем.

И так, проходя комнату раз за разом, шлифовать свой паркет народным способом. Если же у вас паркет совсем состарился, а древесина явно подсохла, из-за его появилось множество дырок и трещин, то без машины циклевочной вам, конечно же, не обойтись. Существует аналог профессиональным машинам – такие же, только маленького размера и меньшей мощности. Плюс их в том, что они помогают справиться с труднодоступными местами и весят мало. Ну а минус в том, что от постоянной работы (если вам понадобится пройти комнатный пол 5–6 раз, то уйдет не меньше нескольких дней) такие ручные маломощные машины ломаются.
Что лучше выбрать – циклевка старого паркета или покупка новых материалов?
Понятное дело, что деревянный пол всегда больше ценился. Хотя многие хозяева старых квартир довольно часто отдают предпочтение ламинату, линолеуму или ковролину. И плюсов и минусов у них также предостаточно. Одни не «терпят» присутствие воды, другие быстро повреждаются под тяжестью крупногабаритных предметов, третьи собирают пыль. Пол можно сделать и плиточным или из керамического гранита. Новинок много – начиная от полимерных полов и заканчивая теплыми, со специальной системой подогрева. Тем не менее, именно древесина всегда считалась экологически чистым материалом, который служит долго, спокойно держит влагу и не сильно подвержен механическим повреждениям.
И плюсов и минусов у них также предостаточно. Одни не «терпят» присутствие воды, другие быстро повреждаются под тяжестью крупногабаритных предметов, третьи собирают пыль. Пол можно сделать и плиточным или из керамического гранита. Новинок много – начиная от полимерных полов и заканчивая теплыми, со специальной системой подогрева. Тем не менее, именно древесина всегда считалась экологически чистым материалом, который служит долго, спокойно держит влагу и не сильно подвержен механическим повреждениям.
Впрочем, свой срок эксплуатации паркетный пол также имеет, а потому, рано или поздно, приводить в порядок вам его все же придется. Для тех, кто не знает, как отциклевать паркет своими руками, лучшим вариантом будет вызвать профессионалов. Компанию следует выбирать из тех, о которых отзывы среди ваших знакомых и в интернете только положительные. Знающая толк в своем деле бригада из 2 человек за день-два и отциклюет пол при помощи специальной машины, и устранит дефекты, и подготовит поверхность к покрытию лаком, а также проведет и лакирование.
После этого этапа вам не желательно вообще заглядывать в комнату первые сутки, пока пол не подсохнет. А уж ходить и проверять качество покрытия – тем более. Если же вы решили все-таки приступить к работам самостоятельно, то проконсультируйтесь – какова толщина планок и из какого материала они сделаны. Допускается при толщине в 8 мм проводить циклевку 3 раза, если 15 мм – 5. Иначе снять полностью верхний слой древесины с царапинами или частичками лака вам попросту не удастся. Как снять лак с дерева – читаем далее.
Как произвести циклевку паркета своими руками — пошаговая схема
Шаг 1: Подготовка
Убираем пол, мусор выносим – вытираем пыль и моем паркет. Если перед началом работ много строительной пыли, то используем пылесос.
Шаг 2: Выбираем инструмент
Для того чтобы выбрать инструмент, определитесь каким способом вы будете циклевать паркет – при помощи профессиональной машины или специальной ручной цикли. В первом случае берете циклевочную машину в аренду, во втором – находите ручное приспособление с ручкой и заточенной поверхностью. Лучше выбрать в строительном магазине инструмент шириной в 5 см.
Лучше выбрать в строительном магазине инструмент шириной в 5 см.
Шаг 3: Подготавливаем участок работы
Участок пола, который планируете обрабатывать, намочите мокрой тряпкой. Подготовьте инструменты. Для работы также приобретите респиратор, так как пыли от циклевки будет достаточно много.
Шаг 4: Приступаем к циклевке
Профессионалы советуют начинать работы с середины комнаты. Далее циклевать необходимо в сторону стен. Для ровного снятия верхнего слоя древесины, постарайтесь равномерно нажимать на инструмент (циклю) обеими руками. Чтобы работалось легче, режущую часть надо время от времени затачивать. При этом каждая полоса должна быть обработана как в прямом, так и обратном направлении.
Шаг 5: Шлифовка
Далее следует следующий процесс – шлифовка. При помощи наждачной бумаги проходим весь паркет снова. Как советуют эксперты, легче работать ногами (наждачную бумагу приклеить к подошве).
Шаг 6: Покрытие лаком
Подготавливаем лак и наносим на чистую поверхность. Ходить по участкам паркета с лаком нельзя до полного высыхания.
Ходить по участкам паркета с лаком нельзя до полного высыхания.
Рекомендации и советы для тех, кто циклюет паркет сам
Конечно, пригласить мастера было бы самым правильным решением, но если средства не позволяют или вы уверены в своих силах на все сто, то можете прислушаться к намим советам и рекомендациям:
- Приводить в порядок (циклевать) старый паркет легче при помощи профессиональной техники. Оборудование должно быть с широкой абразивной лентой. Использовать маленькую шлифовальную машину достаточно тяжело.
- Если паркет сильно поврежден, то лучше использовать ленту для шлифования зернистостью 30. Обработка с использованием ленты меньшей зернистости поможет устранить оставшиеся следы после грубой обработки.
- Дощатые полы советских времен сначала выравнивают вдоль древесных волокон, а затем обрабатывают под небольшими углами (от 7 до 15 градусов). По правилам, паркетный пол диагонально шлифуется по отношению к рисунку укладки. Двигаться нужно равномерно и без рывков.
- При каждом новом проходе шлифовальной машины смещение не должно превышать 85 % ширины барабана. При такой работе боковое колесо двигаться будет в том числе и по обработанной поверхности.
- Если основной машиной не удается добраться до труднодоступных мест, то используется угловая дисковая машинка. Она помогает справиться с участками пола вблизи плинтуса и в углах комнаты. Решить вопрос может и наждачная бумага.
- Если после шлифовки на паркете по-прежнему есть глубокие царапины, то их можно заделать специальной шпаклевкой (наносят тонким слоем, можно взять под цвет древесины). Шпаклевка высыхает порядка 5 часов.
- Лак лучше наносится, если использовать валик из овечьей шерсти. Непосредственно перед тем, как наносить второй слой лака, следует тщательно очистить пол от пыли. Лакировка желательно должна быть в 3 слоя. Чем больше слоев, тем более прочным будет и покрытие. Для идеального результата после каждого высыхания нужно вновь пройтись шкуркой вручную.
- Итак, ваш пол, как новенький. Но чтобы он таковым оставался на многие годы, то реставрировать и обновлять вышеуказанным способом его необходимо каждые 6–7 лет. И не забывайте в рамках восстановительных работ обновленную поверхность древесины обрабатывать антисептиком.
 По правилам, паркетный пол диагонально шлифуется по отношению к рисунку укладки. Двигаться нужно равномерно и без рывков.
По правилам, паркетный пол диагонально шлифуется по отношению к рисунку укладки. Двигаться нужно равномерно и без рывков.Оцените статью: Поделитесь с друзьями!
Как и чем циклевать и шлифовать паркет своими руками
share.in Facebook
share.in Telegram
share.in Viber
share.in Twitter
Среди всех материалов напольного покрытия, самым эстетичным и уютным для большинства владельцев квартир по сей день остается деревянный паркет. Действительно, древесина идеально подходит для создания атмосферы уюта в любой комнате, но при ее использовании в декоре Вашей жилой площади возникает весьма важный вопрос – как сохранить красоту материала и увеличить срок «жизни» пола?
Содержание:
- Циклевка и шлифовка паркета, в чем разница?
- Как циклевать паркет
- Как шлифовать пол
Конечно же периодической циклевки пола вполне достаточно для поддержания первоначального вида напольного покрытия. Но использование автоматического циклевателя или, в худшем случае, ручной цикли сопряжено с множеством трудностей, так как процесс этот весьма долгий и энергозатратный. Много мусора и излишняя громкость делают этот способ ухода за паркетом неудобным, а с появлением на рынке новых машин, еще и устаревшим.
Но использование автоматического циклевателя или, в худшем случае, ручной цикли сопряжено с множеством трудностей, так как процесс этот весьма долгий и энергозатратный. Много мусора и излишняя громкость делают этот способ ухода за паркетом неудобным, а с появлением на рынке новых машин, еще и устаревшим.
В таком случае намного выгоднее просто разобраться как шлифовать пол своими руками, что сэкономит много времени и сил. Но все же давайте детально разберем, нужно ли тратить время на циклевание.
Циклевка и шлифовка паркета, в чем разница?
Итак, что же такое собственноручная циклевка паркета? Это снятие устаревшего и поврежденного слоя с напольного покрытия при помощи как ручного, так и электрического инструмента. Заточенная пластина из металла в таких приборах снимает деревянную стружку с пола, но такая работа трудная и долгая. Также при отсутствии должного умения циклёвка паркета получится более низкокачественной, потому что этот процесс требует определенных практических навыков.
Грубая обработка с помощью крупнозерновой наждачной бумаги спокойно заменяет циклёвку. Процессы схожи между собой, но шлифование менее энергозатратное и шумное занятие. Также крупнозерновая отделка используется для доведения напольного покрытия до более гладкого состояния.
Но все же давайте разберемся в этих вопросах более детально.
Как циклевать паркет
Выше мы разобрались что же это за процесс, теперь рассмотрим вопрос: когда же паркету требуется грубая циклевка?
Как только шероховатости и царапины старого напольного покрытия терпеть уже нет никаких сил, пол требует срочного обновления. В таком случае нужно выбрать способ – ручной или машинный.
Если решить пользоваться обычной ручной циклей, то стоит сразу готовиться к длительной работе, возможно даже придется потратить несколько дней.
- Первое что нужно сделать — вынести всю мебель из комнаты, а плинтуса попросту демонтировать.
- Далее следует подготовка пола, которая состоит из уборки мусора, а потом увлажнения паркета.
- Теперь пол готов и поделив периметр на несколько полос можно начинать обработку. Поступательными равномерными движениями нужно снимать старый слой древесины, сначала вдоль волокон, а после в противоположную сторону.

Но если у вас попросту нет пары свободных дней на обработку пола? Тогда давайте разберем как же правильно циклевать паркет своими руками с помощью специальной машины?
Начнем с того, что такая циклёвка отличается от ручной, ведь гораздо выгоднее выполнить её с помощью барабанной или ленточной шлифовальной машины, оснащенной крупнозернистой наждачной бумагой ( от 24 до 40 Р). В таком случае пара дней работы превратятся во всего лишь несколько часов.
Единственным важным вопросом остается лишь проверка электросети в квартире. Если напряжение не достигает 220 Вт, то нужно подключать машину напрямую к электрощиту.
А вот уже способ работы мало отличается от ручного:
- Также нужно подготовить комнату, освободив ее от вещей и мебели, а также демонтировав плинтуса.
- После увлажнения напольного покрытия, равномерно снимайте старый слой паркета, во время работы с нужной силой нажимая на машину.
- Углы и труднодоступные места циклевать стоит с помощью угловой машины, не стоит лезть ленточной машинкой в место, для которого она не предназначена.
- В случае, если Вы пропустили маленькую шероховатость или трещину, лучше всего будет обработать этот мини-участок вручную с помощью той же крупнозернистой наждачной бумаги.
Вот и все, пол отциклёван и полностью готов к шлифовке.
Как шлифовать пол
Итак, старый слой снят и теперь можно продолжать процесс обновления паркета.
Так как комната уже освобождена от лишних предметов, а пол при циклевке был увлажнен и очищен от мусора, то можно себя поздравить, подготовка к шлифованию завершена.
Этот процесс, в особенности после циклёвки должен проходить в несколько этапов и совершаться нужным инструментом. Чем же люди предпочитают обновлять паркет? Этот процесс может совершаться с помощью:
Каждый вид прибора подойдет для решения определенных задач и стоит детально разобрать, какой агрегат для чего нужен:
Ленточная шлифовальная машина идеально подойдет для обработки пола по всей площади. Ширина ленты и принцип работы позволяют быстро и легко справиться даже с довольно большой площадью обновляемого паркета.
Эксцентриковая машина в силу своей конструкции и функционального предназначения нужна в случае присутствия угловых или закругленных поверхностей.
Вибрационная шлифмашина полезна на заключительном этапе шлифовки, потому что обладает формой утюга, что позволяет спокойно справиться с труднодоступными местами.
Зачастую, достаточно будет наличия лишь машины ленточного типа, но в случае особой планировки комнаты неплохо было бы также иметь под рукой вибрационный агрегат.
Итак, нужный вид шлифмашины подобран, а подготовка комнаты и пола завершена. На всякий случай стоит еще раз внимательно осмотреть паркетное покрытие и вспомнить основные нюансы работы с ленточной шлифовальной машиной, так как особых премудростей в использовании вибрационного типа не требуется:
- Шлифовка осуществляется в диагональном направлении по отношению к укладке покрытия. Перед самим процессом весьма важно правильно подобрать давление наждачной бумаги на поверхность, с которой Вы работаете. От этого зависит качество выполненной работы, ведь недостаточное давление приводит к неровностям и остаткам поврежденной древесины.
- Шлифовка должна происходить таким образом, чтобы в процессе каждая следующая пройденная дорожка перекрывала предыдущую на пару сантиметров.
- Скорость работы с машиной должна быть средней. Если пустить ее слишком быстро или медленно, на паркете останутся выпуклости и углубления.
- В случае внезапного замедления работы шлифмашины, стоит убавить давление инструмента на поверхность.

Теперь можно приступать к первому этапу поверхностной шлифовки:
- Подберите абразив с зернистостью Р60 или Р80;
- С помощью поступательных равномерных движений обработайте основную часть напольного покрытия;
- Далее следует отделка углов и труднодоступных мест;
- Снова пройдитесь и осмотрите пол после работы.
Перед последним этапом нужно зашпаклевать любую щель или зазор с помощью мастики, или смеси с древесной пылью, которая осталась после циклевки и шлифования.
И вот работа уже на финишной прямой.
Способ чистовой отделки не изменен, единственное что отличается – зернистость абразива, которая теперь должна быть от Р100 до Р120.
Выполнив все описанные этапы, остается лишь убрать опилки и пыль, нанести антисептическое средство и покрыть паркет лаком, первый слой которого – грунтовочный. После высыхания, пол снова шлифуется и вот уже тогда наносятся остальные слои.
Вот и все, работа окончена, а напольное покрытие выглядит прекрасно, как новое. Остается лишь один важный вопрос, когда снова придется циклевать паркет? Достаточно повторять вышеописанные действия раз в 6 или даже 8 лет.
Надеемся, что эта статья поможет всем людям, которые решили обновить напольное покрытие своими руками. А в случае отсутствия нужного инструмента, ждем вас на официальном сайте Dnipro-M. Множество электроинструментов и расходных материалов, их описания, характеристики и самое главное – отзывы довольных покупателей, все это поможет как любителю, так и профессионалу в выполнении работ любой сложности. Циклевать и шлифовать своими руками с подходящим инструментом — легко и просто.
Dnipro-M желает вам удачной и продуктивной работы, а также всегда готов помочь инструментом европейского качества по украинской цене.
Правильная циклевка старого паркета своими руками
Паркет Вас не радует, лак потускнел, местами облез, между плашками образовались щели, деревянный пол в пятнах, поверхность стала неровной — это значит: настало время провести циклевку старого паркета.
Что такое циклевка старого паркета своими руками и как ее выполнить!
Как сделать циклевку паркета самостоятельно, и что для этого нужно? Существует несколько видов шлифовальной техники и каждая из них, зачем-то нужна. Чтобы выполнить все своими руками и остаться довольным, читайте эту статью!
Все фотографии на сайте — это наши работы!
Нажав сюда, Вы можете увидеть адреса и фотографии последних наших работ
Циклевать старый пол самостоятельно надо уметь!
Мы написали эту статью, чтобы Вы имели представление о том, что это, и как это качественно сделать!
Смотрите фотографии циклевки паркета до и после!
Сначала деревянный пол обрабатывается барабанной машиной, типа СО-2, или ленточной, типа Hummel. Отличие между ними в абразивной ленте и технике ее заправки. На СО-2 лента зажимается поперечными вальцами и это место на барабане более плотное, следовательно, в процессе циклевки место зажима будет оказывать дополнительное давление на покрытие, что может привести к появлению «дроби», особенно на мягких породах дерева. На машине Hummel абразивная лента клееная и одевается на два шкива, т.е. как бы бесконечная и обработка полов более равномерна. По технике циклевки и присутствию пыли в процессе работы машины практически идентичны, даже Хумелем сделать «яму» проще, т.к. площадь соприкосновения абразива с полом у него меньше.
На машине Hummel абразивная лента клееная и одевается на два шкива, т.е. как бы бесконечная и обработка полов более равномерна. По технике циклевки и присутствию пыли в процессе работы машины практически идентичны, даже Хумелем сделать «яму» проще, т.к. площадь соприкосновения абразива с полом у него меньше.
Циклевка старого паркета, или как правильно отциклевать паркет самому?
Первым делом Вам надо удалить старый лак, выровнять пол и снять верхний слой древесины. Существует несколько номеров абразивного материала — от P16 до P220 и мельче. Нельзя нарушать последовательность смены номеров, ибо основные операции Вы проводите первым номером, остальные нужны для удаления воздействия абразива на покрытие. Каждый абразив удаляет полоски, риски и т.д. предыдущего абразива, но оставляет свои, следовательно, надо закончить обрабатывать мелкой шкуркой, чтобы полоски были не видны при лакировке-это называется шлифовка паркета. Надо понять, что номер P40 уберет полоски, оставленные P36,а вот если вместо P40 для экономии вы пройдете P80, полосы от грубого зерна будут видны.
В свете вышесказанного, перед вами стоит задача выбора первого номера абразива так, чтобы выполнить поставленную задачу и при этом нанести наименьшие воздействия на пол. Как это сделать? Тут решающее значение имеет опыт и мастерство! Циклюя самостоятельно в первый раз, начинайте с самого «ненужного» помещения. Перейдя на основное, успеете преобрести хоть какой-нибудь, да опыт!
Теперь о том, как грамотно провести мероприятия по циклевке! Итак, определившись с первым номером абразива можно приступать к циклевке. Если лак «тяжелый», его много, пол неровный лучше всего начинать движение под 45 градусов от направления клепок или досок, затем опять под 45 градусов, но в другую сторону и потом по направлению света, т.е. от окна. Опускать и поднимать барабан надо очень плавно и в движении, чтобы не оставлять ям. Это одна из основных ошибок, стоит дать машине поработать на месте хоть пол секунды, как сразу получите яму, которая проявится при лакировке! На этот момент следует обратить особое внимание!!!! При работе первым абразивом лучше тащить машину на себя, двигаясь спиной вперед, а возвращаться назад вхолостую. В дальнейшем циклевать пол можно в обоих направлениях. Внимание! Во время движения лицом вперед надо придерживать машину, при движении на себя наоборот тащить. Циклюя полы, мастер должен перекрывать каждым новым проходом предыдущий на треть!
В дальнейшем циклевать пол можно в обоих направлениях. Внимание! Во время движения лицом вперед надо придерживать машину, при движении на себя наоборот тащить. Циклюя полы, мастер должен перекрывать каждым новым проходом предыдущий на треть!
Итак, циклевка машиной закончена, но что делать с примыканиями! То есть с местами вдоль стен, куда вы не смогли подъехать циклевочной машиной. В этом случае используются угловые машины типа «Flip» или на крайний случай УШМ с насадкой. В принципе ничего сложного, главное правильно менять абразив, работать плавно, не торопливо, не пытаться давить на машинку, не нагибать ее углом. Как говориться, торопливость нужна при ловле блох, обрабатывая примыкания можно так изрезать паркет, что не каждый мастер сможет исправить. Обработку примыканий можно проводить в середине процесса, можно в конце.
Вот циклевка паркета видео:
Теперь рассмотрим что это за машина ТРИО и зачем она нужна! Это плоскошлифовальная машина, которая обрабатывает поверхность пола плоскостью. Она имеет вращающуюся плоскость, на которую крепятся три диска с абразивом, крутящихся в противоположную сторону. На ней также используются абразивы разных номеров, последовательность смены которых нельзя нарушать. Эта машина обрабатывает за раз большую площадь с меньшим давлением, что позволяет лучше вышлифовать пол. После обработки паркет или доска становятся более ровными и гладкими, структура древесины лучше проявляется, хотя если вы надеетесь выровнять покрытие или снять старый слой лака, используя лишь ТРИО, Вы будете неприятно удивленны, как сложно это сделать. По большому счету, она лишь доводочная машина. Используя, необходимо плавно шлифовать помещение, не торопясь, но и не стоять на одном месте. Расход абразива одна заправка на 15-20м.кв. Чем агрессивнее лак, которым собираются лакировать, чем сложнее и экзотичнее древесина, не говоря уже про тонировку, тем более мелким абразивом надо заканчивать шлифовку, иногда приходится проходить специальными сетками номеров 180 или 220.
Она имеет вращающуюся плоскость, на которую крепятся три диска с абразивом, крутящихся в противоположную сторону. На ней также используются абразивы разных номеров, последовательность смены которых нельзя нарушать. Эта машина обрабатывает за раз большую площадь с меньшим давлением, что позволяет лучше вышлифовать пол. После обработки паркет или доска становятся более ровными и гладкими, структура древесины лучше проявляется, хотя если вы надеетесь выровнять покрытие или снять старый слой лака, используя лишь ТРИО, Вы будете неприятно удивленны, как сложно это сделать. По большому счету, она лишь доводочная машина. Используя, необходимо плавно шлифовать помещение, не торопясь, но и не стоять на одном месте. Расход абразива одна заправка на 15-20м.кв. Чем агрессивнее лак, которым собираются лакировать, чем сложнее и экзотичнее древесина, не говоря уже про тонировку, тем более мелким абразивом надо заканчивать шлифовку, иногда приходится проходить специальными сетками номеров 180 или 220. Мысль о том, что ТРИО не может испортить работу наивна, эта машина тоже может оставить риски и полоски, которые проявятся при лакировке или при тонировке (смотрите пример ошибок тонировки паркета ). Давление на пол машины так мало, что ее можно использовать для межслоевой шлифовки с помощью специальных сеток.
Мысль о том, что ТРИО не может испортить работу наивна, эта машина тоже может оставить риски и полоски, которые проявятся при лакировке или при тонировке (смотрите пример ошибок тонировки паркета ). Давление на пол машины так мало, что ее можно использовать для межслоевой шлифовки с помощью специальных сеток.
Итак, резюме: Провести циклевку самостоятельно можно, но вот описать все сложности и нюансы, возникающие в процессе работы очень непросто. Даже моменты, кажущиеся нам простыми, могут поставить в затруднение неопытного человека.
Вывод: сделать можно, но для получения прекрасного результата, при этом избавив себя от головной боли, обращаться надо к профессионалам!
Как циклевать паркет своими руками (самому вручную
Со временем лаковое покрытие паркетной доски стирается. На плашках могут появиться царапины и щербины. Это значит, что пришла пора паркет обновить, восстановив не только его внешний вид, но и защитное покрытие. Как правильно циклевать паркет своими руками – читайте в нашей статье. А сам паркет можно посмотреть тут.
А сам паркет можно посмотреть тут.
Как правильно циклевать паркет? Это достаточно трудоемкая процедура, требующая большой аккуратности. Если вы готовы взять в аренду специальный инструмент и предварительно изучить, как циклевать паркет самому, то все получится.
- Полностью освобождаем комнату от мебели, демонтируем плинтус. Паркет перед шлифовкой не моем.
- Удаляем старое покрытие и неровности (грубая циклевка) с помощью паркетошлифовальной машины барабанного или ленточного типа и крупных абразивов № 24-40. Периметр, углы и труднодоступные места обрабатываем углошлифовальной машиной.
- После грубой шлифовки на поверхности дерева могут остаться волнообразные следы и даже царапины. Они удаляются на следующем этапе шлифовки абразивом со средней зернистостью (№ 60-80). Заодно окончательно удалятся остатки старого покрытия.
- Для следующего этапа шлифовки нам понадобится абразив № 100, 120 или 150. Прежде чем браться за этот этап, освобождаем пылесборник шлифмашины. Собранная при помощи тонкого абразива пыль понадобится нам для изготовления шпатлевки.
- Шпатлевание щелей, трещин, выпавших сучков, сколов. В качестве заполнителя можно использовать пыль, собранную после тонкой шлифовки и специальную связующую смолу. Смешав два этих ингредиента (в пропорциях, указанных в инструкции к смоле), вы получите шпатлевку, идеально соответствующую цвету вашего паркета.
- После полного высыхания шпатлевки производим финишную шлифовку (полировку) паркета, которая сделает поверхность пола абсолютно гладкой и удалит остатки шпатлевки.
- Тщательно обеспыливаем помещение и шпателем, S-образными движениями наносим слой грунтовочного лака. Грунтовка снижает гигроскопичность древесины и не дает ей изменить цвет от прямого контакта с лаком.
Специальные грунтовки для паркета бывают нескольких видов. Выбирать их нужно с учетом вида древесины. Однокомпонентная нитрогрунтовка подойдет для гигроскопичной древесины (дуб, орех, ироко). Полиуретановые грунтовки идеальны для дерева с высоким содержанием смол и масел (экзотические породы – тик, палисандр).
Для древесины светлых сортов можно подобрать осветляющие виниловые грунтовки или специальные грунтовки с защитой от ультрафиолета. - После грунтовки может понадобиться межслойная шлифовка. Она делается для удаления поднявшегося во время грунтовки ворса. Используем тонкий абразив, которым пользовались для финишной шлифовки паркета.
- Обеспыливаем помещение после межслойной шлифовки.
- Лакируем поверхность в 3-5 слоев. Для нанесения лака используют валик, широкую кисть или краскопульт. Очень важно следовать инструкции по применению купленного вами лака и соблюдать время для отвердевания каждого слоя.
 Собранная при помощи тонкого абразива пыль понадобится нам для изготовления шпатлевки.
Собранная при помощи тонкого абразива пыль понадобится нам для изготовления шпатлевки. Для древесины светлых сортов можно подобрать осветляющие виниловые грунтовки или специальные грунтовки с защитой от ультрафиолета.
Для древесины светлых сортов можно подобрать осветляющие виниловые грунтовки или специальные грунтовки с защитой от ультрафиолета.
Как циклевать паркет вручную, без шлифовальной машины?
Для этого можно использовать ручную циклю. Она подойдет также для восстановления небольших участков паркета. Работать начинаем от центра комнаты к стенам. Каждый участок необходимо пройти в двух направлениях. После первичной шлифовки паркета вручную используем шкурки разной зернистости – от грубой к тонкой.
Наш совет: прежде чем решить, как циклевать паркет, надо проанализировать его состояние. Если это паркет 50-летней выдержки, рассохшийся и скрипящий, то вполне вероятно, что его проще будет полностью заменить.
Циклевка паркета своими руками в домашних условиях — Спец Паркет Групп
Как бы ни менялась мода на дизайн помещений, паркетные полы всегда остаются популярными. Эта вечная классика интерьеров будет актуальной, ведь дерево известно своими отличными эксплуатационными характеристиками и долговечностью. Благодаря этой статье вы узнаете, как правильно циклевать паркет своими руками. Собственноручно положенный пол – предмет гордости на долгие годы.
Зачем нужно циклевание
Процесс ручного скобления (циклевки) паркета Технология предполагает выравнивание деревянных, а в некоторых случаях и пластмассовых, покрытий скоблением. Она может выполняться ручным или механизированным оборудованием. Предназначение состоит в удалении незначительных неровностей, образующихся на поверхности после порезки инструментом. Глубина такой полировки составляет всего сотые или десятые доли миллиметра, поэтому поверхность самой доски не повреждается.
Глубина такой полировки составляет всего сотые или десятые доли миллиметра, поэтому поверхность самой доски не повреждается.
Процедура необходима в двух случаях:
- если паркет только что уложен;
- для реставрации старого покрытия.
Циклёвка деревянного пола своими руками является промежуточным этапом между осуществлением грубой обработки в виде порезки, строгания и фрезеровки, и полировкой покрытия. Она позволяет качественно уложить настил, который прослужит долгие годы, а также восстановить уже изношенные материалы и придать им первозданный вид. Как циклевать паркет своими руками? Важно ознакомиться с процедурой и максимально тщательно соблюдать её этапы. Чем старательнее придерживаться технологии, тем лучше получится отциклевать поверхность, и паркет будет смотреться намного привлекательнее.
Технология циклёвки
Процесс циклевки паркета ручной циклевочной машинкой Прежде всего, давайте определимся, какие инструменты понадобятся для процедуры. Если будет использоваться специальная машинка, в которой в комплекте идут все необходимые насадки, следует вооружиться только средствами индивидуальной защиты. При ручной циклёвке вам нужно приобрести:
Если будет использоваться специальная машинка, в которой в комплекте идут все необходимые насадки, следует вооружиться только средствами индивидуальной защиты. При ручной циклёвке вам нужно приобрести:
- крупнозернистую наждачную бумагу с различными размерами зерна – 24, 36, 40;
- перчатки и респиратор;
- болгарку для ускорения обработки.
Как циклевать пол своими руками, если не хочется тратить уйму денег на дорогостоящее оборудование или наём специалистов? Конечно же, каждый желает, чтобы процедура не стала затяжной и как можно быстрее закончилась. Как самому циклевать паркет, если нет специальных навыков? Для ускорения обработки можно закрепить наждачную бумагу на круг болгарки. Скорость вращения при отделке не должна быть выше 12000 оборотов. Процедура позволит обработать поверхность площадью 50 квадратных метров всего за 1 день. Для такой комнаты понадобится около 5 респираторов и 2 упаковки наждачной бумаги по 10 шт. в каждой.
Как циклевать паркетную доску и при этом потратить намного меньше денег, по сравнению с приобретением специальных материалов и заказом работы специалистов? Это возможно. Понадобится совсем немного времени и усилий. Очень привлекательно то, что добиться отличного внешнего вида полов можно даже при применении обычной доски, не предназначенной для напольного использования.
Как и в случае со специальными материалами, важна правильная укладка. Недопустимо укладывать деревянные полы на неровную поверхность. С годами это приведёт к значительным деформациям и в итоге – к необходимости переделывать всю работу заново.
Для того чтобы циклёвка паркета своими руками проходила легче, необходимо предварительно смочить поверхность. Тогда в процессе обработки будет выделяться намного меньше пыли. Уже после завершения этой процедуры приступайте к шлифовке и лакированию полов.
У нас также можно посмотреть видео о том, как циклевать паркет своими руками. С такой работой может справиться даже непрофессионал. Восстановить красоту деревянного пола значительно дешевле, чем заново его перестилать.
Восстановить красоту деревянного пола значительно дешевле, чем заново его перестилать.
Как отциклевать паркет своими руками
Тем, кто хочет отциклевать паркет самостоятельно, но не знает, как это сделать, пригодится немного информации.
- Для самостоятельной циклевки паркета на разных стадиях понадобятся:
- барабанная циклевочная машина;
- плоскошлифовальная машина;
- угловая шлифовальная машина;
- рулонная наждачная бумага;
- специальные валики для лака;
- паркетный лак;
- вспомогательные инструменты: гаечные ключи, ножницы;
- пылесос.
Вся процедура ремонта паркета состоит из нескольких этапов.
Подготовительный этап
Перед тем, как отциклевать паркет своими руками, необходимо полностью освободить пол от мешающих предметов и хорошо его вымыть. Если не знаете всех тонкостей этого дела, то посмотрите статью о том, можно ли мыть паркет и как это делать.
- Затем:
- Выступающие шляпки гвоздей или глубоко вбить или удалить, если это не повредит целостности паркета.
- Снять плинтусы.
- Если обнаружатся плохо закрепленные планки, их обязательно нужно закрепить. Как это делать описано в статье о том, как обновить старый паркетный пол.
Приступаем к самой циклевке паркета своими руками
Четвертая часть. Вначале применяется грубая обработка поверхности, в результате которой снимается старый лак и небольшой слой дерева, чтобы выровнять плоскость.
Для этого используется электроинструмент барабанного типа с крупнозернистой наждачной бумагой. По мере вырабатывания абразива, ее следует заменять.
Направление движения инструмента зависит от способа укладки паркета.
Укладка елочкой – машина идет вдоль стен.
Прямолинейная (палубная укладка) – по диагонали.
Осуществлять контакт барабана с полом и разрывать его можно только во время вращения. Иначе на поверхности останутся впадины.
Как правило, выполняется два прохода.
Во время циклевки — соберите паркетную пыль в специальный мешок, она нам еще пригодится.
Добиться идеального качества такой обработкой не получается. Она применяется только для выравнивания серьезных неровностей. Этап заканчивается, когда все значительные дефекты заглажены.
Мелкая шлифовка на этапе циклевки
Это — пятая часть, процедура выполняется плоскошлифовальным инструментом.
Обычно достаточно трех проходов, во время которых используется все более мелкая наждачная бумага. В процессе убираются все полосы и мелкие огрехи, оставшиеся после предыдущей черновой операции.
Шестой этап. Последний этап механической обработки поверхности паркета – это шлифование углов и других труднодоступных мест.
Производится с помощью так называемого «сапожка», угловой электрической шлифмашинки круговыми движениями. При желании эти же действия можно выполнить и другими способами.
Например, используя болгарку со специальными насадками.
На этом основной процесс циклевки паркета в квартире своими руками закончен и можно приступать к окончательной отделке пола.
Седьмой этап. Сначала все видимые зазоры тщательно шпаклюются специальным составом грунтовки для паркета, в который добавляется мелкая фракция древесной стружки, образовавшейся во время шлифования.
Для этого стружку необходимо собрать и не выбрасывать, когда циклюете пол.
Благодаря этому, места заделки будут совершенно незаметны.
Восьмой шаг. После того, как шпаклевка затвердеет, весь пол снова шлифуется самой мелкой наждачкой, опять же, плоскошлифовальной машинкой.
Девятый шаг. Перед нанесением лака пол обязательно нужно тщательно пропылесосить. При этом пылесос должен быть достаточно мощным, чтобы гарантировано полностью убрать пыль и мусор.
Десятый шаг. На заключительной стадии в три слоя наносится лак. Как это делать — лучше узнать из статьи о том, как покрыть паркет лаком своими руками.
После высыхания каждого из них проводится тонкая шлифовка. На этом ремонт заканчивается. Его результата будет достаточно на несколько лет.
Для заказа лакировки и циклевки паркета — обращайтесь в раздел по отделке паркета или на страницу контакты.
Apache Arrow: чтение DataFrame с нулевой памятью
Первой подсказкой был Томас Вольф, имеющий отношение к Apache Arrow. Apache Arrow — это проект, начатый Уэсом МакКинни с целью создания интерфейса для обмена данными:
Apache Arrow — это кросс-языковая платформа для разработки данных в памяти. Он определяет стандартизированный независимый от языка формат столбчатой памяти для плоских и иерархических данных, организованный для эффективных аналитических операций на современном оборудовании. Он также предоставляет вычислительные библиотеки, потоковую передачу сообщений с нулевым копированием и межпроцессное взаимодействие.[1]
Что это означает?
До Arrow стандартным способом обмена данными между любым приложением или библиотекой было сохранение их на диск тем или иным способом. Поэтому, если библиотека .NET Core хочет передать данные в Python для анализа данных, есть вероятность, что кто-то выпишет файл (например, csv, json, Parquet,…), а затем снова прочитает его с помощью Python. Оба шага, запись (сериализация) и чтение (десериализация) являются дорогостоящими и медленными — и чем больше набор данных, тем больше времени требуется для выполнения каждого из них.
Что, если бы существовал способ обмена данными напрямую через рукопожатие и нулевое копирование? Это может выглядеть так: .NET начнет болтать с Python, укажет на кучу данных в памяти и будет примерно так: Привет, приятель, теперь это твое . И Python мог напрямую запрыгнуть на него, не таща его из одного места в другое. Разве это не было бы фантастически?
В этом вся суть Apache Arrow.
Это заставило меня задуматься — как я могу использовать Arrow? Изучив исходный код Hugging Face, я узнал, что проект использует PyArrow для чтения данных.До этого я связывал PyArrow с Parquet, столбчатым форматом хранения с высокой степенью сжатия. Итак, Parquet — это способ, которым Arrow обменивается данными? (Спойлер: это не так)
Традиционно данные хранятся на диске построчно. Столбцовое хранилище возникло из-за необходимости анализировать большие наборы данных и эффективно их агрегировать. Аналитика данных меньше интересуется строками данных (например, одна транзакция клиента, один журнал вызовов и т. Д.), А их агрегированными данными (например, общая сумма, потраченная клиентом, общее количество минут звонков по регионам,…).
Хранилище, ориентированное на строки и столбцы (адаптировано из [4] с набором данных Palmer Station Penguin)
Это привело к изменению ориентации: вместо того, чтобы хранить его строка за строкой, столбчатое хранилище упорядочивает данные столбец за столбцом.
Parquet — это столбчатый формат файла, который имеет два основных преимущества [4]:
- Высокая степень сжатия: Хотя файлы .json или .csv по умолчанию не сжимаются, Parquet сжимает данные и, следовательно, экономит много места на диске. Таблицы обычно состоят из столбцов с большим количеством уникальных значений (высокая мощность; подумайте об уникальном идентификаторе пользователя ) и столбцов с небольшим количеством уникальных значений (низкая мощность; подумайте о стране ).Чем ниже мощность, тем лучше сжатие (может) работать — подробнее об этом в следующем разделе.
- Запрос файла / выталкивание фильтра: Удалите ненужные данные перед их чтением. Это сокращает время загрузки и оптимизирует потребление ресурсов. Если вам нужны только два столбца из таблицы с тысячами столбцов, вам не нужно сканировать все строки, чтобы получить два атрибута — вы напрямую извлекаете столбец целиком
Чтобы лучше понять разницу между Parquet и Arrow, мы нужно будет сделать объезд и получить некоторую интуицию для сжатия.Сжатие файлов само по себе огромная тема. Ниже приводится упрощенное повествование, отфильтрованное на основе моего собственного понимания темы. Это отступление поможет ответить на эти два вопроса:
- Как Parquet удается уменьшить размер файла до такого маленького размера?
- Чем паркет отличается от Arrow?
Подбросьте монету
Представьте, что вы подбрасываете монету десять раз и записываете результат:
[Голова, Голова, Голова, Голова, Хвост, Хвост, Хвост, Голова, Хвост, Хвост]
Теперь попробуйте сказать результат вслух? Скорее всего, вы сократите его и скажете что-то вроде «4 раза голова, 3 раза хвост, голова и 2 раза хвост» :
[4 x голова, 3 x хвост, голова, 2 x хвост]
Это сжатие в действии (описанный алгоритм называется Run-length encoding [8]).Мы склонны естественно видеть закономерность и сокращать. Алгоритм сжатия тоже делает это — только с большей вычислительной мощностью и сложными правилами. Но этого примера должно быть достаточно, чтобы помочь нам понять ключевое различие: в то время как .csv использует буквальный подход и описывает каждую отдельную запись, Parquet сокращает (без потери информации).
Этого простого примера достаточно, чтобы понять, почему степень сжатия может сильно различаться. Например, если порядок сортировки не имеет значения, и вас просто интересует общее количество вхождений заголовка и хвоста, вы можете сначала отсортировать список, а затем сжатая версия будет выглядеть так:
[5 x Head, 5 x Tail]
Подразумевается, что если мы сначала отсортируем набор данных по всем столбцам, прежде чем сохранить его в Parquet, размер файла будет меньше по сравнению с несортированным.Степень сжатия будет тем выше, чем меньше мощность. Ожидается, что степень сжатия для каждого столбца будет уменьшаться по мере того, как он находится в порядке сортировки.
Стрелка сжата?
Благодаря этому мы получили некоторое представление о том, почему файлы Parquet настолько малы по сравнению с несжатыми файлами .csv. Но как это связано со Стрелой?
Оказывается, это как раз одно из ключевых отличий. Паркет очень эффективно хранится на диске. А с помощью фильтра вниз вы можете уменьшить объем считываемых данных (т.е. выбрав только те столбцы, которые вам действительно нужны). Но когда вы хотите выполнить операции с данными, вашему компьютеру все равно необходимо распаковать сжатую информацию и занести ее в память. [2]
Стрелка, с другой стороны, — это формат с отображением в память. В своем блоге Уэс МакКинни резюмирует это следующим образом:
«Конструкция сериализации стрелок обеспечивает« заголовок данных », который описывает точное расположение и размеры всех буферов памяти для всех столбцов в таблице.Это означает, что вы можете отображать в памяти огромные наборы данных размером больше ОЗУ и оценивать алгоритмы в стиле панд на их месте, не загружая их в память, как сейчас с пандами. Вы можете прочитать 1 мегабайт из середины таблицы размером 1 терабайт, и вы платите только за выполнение этих случайных чтений на общую сумму 1 мегабайт ». [6]
Короче говоря, приложения могут напрямую работать с набором данных, хранящимся на диске, без необходимости полностью загружать его в память. Если вы помните первоначальный твит — это именно то, что там происходило.
Теперь давайте рассмотрим эти форматы данных. В качестве образца данных я использую набор данных Palmer Station Penguin. Поскольку он содержит только 350 строк, я передискретизирую его до 1 миллиона, чтобы разница в производительности стала более очевидной:
Запись файлов
В качестве следующего шага я записываю файлы на диск в трех форматах:
- csv ( DataFrame с пропущенными значениями)
- Parquet (DataFrame с отсутствующими значениями)
- Arrow (DataFrame с отсутствующими значениями и без них)
Обратите внимание, что Arrow можно преобразовать в pandas только без выделения памяти (= нулевая копия) при определенных условиях.Один из них: не должно быть значений NaN. Чтобы сравнить производительность с нулевым копированием и без него, я записываю файл Arrow один раз с пропущенными числовыми значениями и без них.
Результирующие размеры файлов:
Сравнение размеров файлов
Parquet, как и ожидалось, является самым маленьким файлом — несмотря на случайную последовательность (перед записью файла не производилась сортировка), он показывает степень сжатия 80%. Arrow лишь немного меньше csv. Причина в том, что csv сохраняет даже числовые значения в виде строк, что занимает больше места на диске.Во всех случаях разница в размерах файлов с пропущенными значениями и без них незначительна (<0,5 МБ).
Время чтения
Теперь ключевая часть: скорость чтения. Сколько времени нужно, чтобы рассчитать среднюю длину ласт?
- csv
- Parquet
- Стрелка с файловым API (
OSFile (...)) - Стрелка как API карты памяти (
memory_map (...)) с пропущенными значениями / NaN - Стрелка как API карты памяти (
memory_map (...)) без пропущенных значений
Время каждой из трех функций дает следующие результаты:
Сравнение производительности: время, необходимое для чтения столбца и вычисления среднего значения
Неудивительно, что csv — самый медленный вариант. Требуется прочитать 200 МБ, проанализировать текст, отбросить все столбцы, кроме длины флиппера, а затем вычислить среднее значение.
Parquet в ~ 60 раз быстрее, так как нет необходимости анализировать весь файл — считываются только необходимые столбцы.
Arrow с пропущенными значениями примерно в 3 раза быстрее, чем Parquet, и почти в ~ 200 раз быстрее, чем CSV.Как и Parquet, Arrow может ограничиться чтением только указанного столбца. Что делает его быстрее, так это то, что нет необходимости распаковывать столбец.
Обратите внимание, что разница между чтением файлов Arrow с отображением в память с нулевым копированием и без него означала еще ~ 3-кратное повышение производительности (т. Е. Нулевое копирование в целом примерно в 600 раз быстрее, чем csv, и ~ в 9 раз быстрее, чем Parquet).
Что удивительно: Arrow с файловым API работает даже медленнее, чем Parquet. Что происходит?
Потребление памяти
Чтобы ответить на этот вопрос, давайте посмотрим на потребление памяти.Сколько оперативной памяти потребляет каждый файл, если мы читаем один столбец?
Вот результаты:
Сравнение производительности: память, потребляемая для чтения столбца
Самое примечательное: стрелка с файловым API занимает 189 МБ — это почти весь размер файла (даже если мы читаем только один столбец ?!). Ответ содержится в документации:
«[…] OSFile выделяет новую память при каждом чтении, как объекты файлов Python». [3]
При использовании OSFile весь файл сначала считывался в память.Теперь понятно, почему эта операция была медленнее, чем Parquet, и потребляла больше всего памяти!
Однако с помощью функции отображения памяти и с заполненными значениями NaN DataFrame pandas был создан непосредственно поверх сохраненного файла Arrow. Без копирования: 0 МБ ОЗУ! Неудивительно, что это был самый быстрый вариант.
Вы можете найти весь Jupyter Notebook здесь 📝
Мне есть что узнать о Arrow. На данный момент я узнал следующее: нельзя есть пирог и есть его.Существует компромисс между [7]:
- Оптимизировать для дискового пространства / длительного хранения на диске → Parquet
- Оптимизировать для обмена данными и быстрого поиска → Arrow
Прирост производительности как Parquet, так и Arrow составляет значимо по сравнению с csv. При сохранении Arrow на диск он занимает больше места, чем Parquet. Однако Arrow превосходит Parquet с точки зрения скорости чтения — как по времени, так и по потреблению памяти. Представленные примеры (вычислить среднее значение одного столбца / столбца чтения) только поверхностны — я ожидаю, что с более сложными запросами и большими наборами данных стрелка будет сиять еще больше.
Пока Arrow читается с функцией отображения памяти, скорость чтения невероятна. В лучшем случае в наборе данных нет пропущенных значений / NaN. Тогда PyArrow сможет творить чудеса и позволить вам работать с таблицей, почти не потребляя памяти.
Будущее действительно уже здесь — и это потрясающе!
Я буду продолжать писать о Python, данных и технологиях — я буду рад встретиться с вами в Twitter ✨
Большое спасибо Yingying за подробный обзор и отличные отзывы! 👏
[1] Apache Arrow, целевая страница (2020), веб-сайт Apache Arrow
[2] Apache Arrow, FAQ (2020), веб-сайт Apache Arrow
[3] Apache Arrow, файлы с отображением на диске и в памяти ( 2020), Документация по привязкам Python для Apache Arrow
[4] J.LeDem, Apache Arrow и Apache Parquet: Почему нам нужны разные проекты для столбчатых данных, на диске и в памяти (2017), KDnuggets
[5] Дж. Ледем, План столбцов: Apache Parquet и Apache Arrow (2017), Дремио
[6] В. МакКинни, Apache Arrow и «10 вещей, которые я ненавижу в пандах» (2017), Блог
[7] У. МакКинни, Некоторые комментарии к блогу Дэниела Абади об Apache Arrow (2017), Блог
[8] Википедия, Кодирование длин серий (2020), Википедия
Пример кода: объединение и реляционализация данных
В этом примере используется набор данных, который был загружен с http: // everypolitician.org / в
Образец набора данных Корзина в Amazon Simple Storage Service (Amazon S3):
s3: // awsglue-datasets / examples / us-законодатели / все . Набор данных содержит данные в
Формат JSON о законодателях США и местах, которые они занимали в
Дом США
Представители и Сенат, и был немного изменен и стал доступен в
общедоступная корзина Amazon S3 для целей этого руководства.
Вы можете найти исходный код этого примера в файле join_and_relationalize.py
файл в образцах AWS Glue
репозиторий на сайте GitHub.
Используя эти данные, в этом руководстве показано, как сделать следующее:
Используйте сканер AWS Glue для классификации объектов, хранящихся в общедоступном Amazon S3.
ведро и спасти их
схемы в каталог данных AWS Glue.Изучите метаданные и схемы таблицы, полученные в результате обхода.
Напишите сценарий Python для извлечения, передачи и загрузки (ETL), который использует метаданные в
то
Каталог данных для выполнения следующих действий:Объедините данные из разных исходных файлов в единую таблицу данных (которая
является,
денормализовать данные).Отфильтруйте объединенную таблицу в отдельные таблицы по типу законодателя.
Запишите полученные данные в отдельные файлы Apache Parquet для последующего анализа.
Самый простой способ отладки скриптов Python или PySpark — создать конечную точку разработки.
а также
запустите свой код там. Мы рекомендуем начать с настройки конечной точки разработки.
работать
в.Для получения дополнительной информации см. Просмотр свойств конечной точки разработки.
Шаг 1:
Сканирование данных в корзине Amazon S3
Войдите в Консоль управления AWS и откройте консоль AWS Glue по адресу https: // console.aws.amazon.com/glue/.
Следуя инструкциям из раздела Работа со сканерами в консоли AWS Glue, создайте новый сканер, который может сканировать
s3: // awsglue-datasets / examples / us-законодатели / весь набор данныхв базу данных с именем
законодателейв каталоге данных AWS Glue.Данные примера уже есть в этом общедоступном Amazon S3.
ведро.Запустите новый поисковый робот, а затем проверьте базу данных
законодателей.Искатель создает следующие таблицы метаданных:
человека_jsonmemberships_jsonорганизации_jsonevents_jsonarea_jsonстраны_r_json
Это полунормализованный набор таблиц, содержащих законодателей и их
истории.
Шаг 2:
Добавить шаблонный скрипт в блокнот конечной точки разработки
Вставьте следующий шаблонный сценарий в записную книжку конечной точки разработки для импорта
необходимые библиотеки AWS Glue и настройте один GlueContext :
import sys
от awsglue.преобразует импорт *
из awsglue.utils import getResolvedOptions
из pyspark.context импортировать SparkContext
из awsglue.context импортировать GlueContext
из задания импорта awsglue.job
glueContext = GlueContext (SparkContext.getOrCreate ())
Шаг 3:
Изучите схемы из данных в каталоге данных
Затем вы можете легко создать динамический фрейм для изучения из каталога данных AWS Glue,
и изучите схемы данных.Для
Например, чтобы увидеть схему таблицы people_json , добавьте в свой
ноутбук:
person = glueContext.create_dynamic_frame.from_catalog (
база данных = "законодатели",
table_name = "person_json")
print "Count:", person.count ()
person.printSchema ()
Вот результат печати вызовов:
Количество: 1961
корень
| - family_name: строка
| - имя: строка
| - ссылки: массив
| | - элемент: структура
| | | - примечание: строка
| | | - url: строка
| - пол: строка
| - изображение: строка
| - идентификаторы: массив
| | - элемент: структура
| | | - схема: строка
| | | - идентификатор: строка
| - other_names: массив
| | - элемент: структура
| | | - примечание: строка
| | | - имя: строка
| | | - lang: строка
| - sort_name: строка
| - изображения: массив
| | - элемент: структура
| | | - url: строка
| - given_name: строка
| - Birth_date: строка
| - id: строка
| - contact_details: массив
| | - элемент: структура
| | | - тип: строка
| | | - значение: строка
| - death_date: строка
Каждый человек в таблице является членом какого-либо органа Конгресса США.
Чтобы просмотреть схему таблицы memberships_json , введите следующее:
memberships = glueContext.create_dynamic_frame.from_catalog (
база данных = "законодатели",
table_name = "memberships_json")
print "Count:", членство.считать()
memberships.printSchema ()
Результат выглядит следующим образом:
Количество: 10439
корень
| - area_id: строка
| - on_behalf_of_id: строка
| - идентификатор_организации: строка
| - роль: строка
| - person_id: строка
| - законодательный_период_id: строка
| - start_date: строка
| - end_date: строка
организации партии и две палаты Конгресса, Сенат
и Палата представителей.Чтобы просмотреть схему таблицы organization_json ,
введите следующее:
orgs = glueContext.create_dynamic_frame.from_catalog (
база данных = "законодатели",
table_name = "organization_json")
print "Count:", orgs.count ()
orgs.printSchema ()
Результат выглядит следующим образом:
Количество: 13
корень
| - классификация: строка
| - ссылки: массив
| | - элемент: структура
| | | - примечание: строка
| | | - url: строка
| - изображение: строка
| - идентификаторы: массив
| | - элемент: структура
| | | - схема: строка
| | | - идентификатор: строка
| - other_names: массив
| | - элемент: структура
| | | - lang: строка
| | | - примечание: строка
| | | - имя: строка
| - id: строка
| - имя: строка
| - места: int
| - тип: строка
Шаг 4:
Фильтровать данные
Затем оставьте только те поля, которые вам нужны, и переименуйте id в
org_id .Набор данных достаточно мал, чтобы вы могли просмотреть все.
toDF () преобразует DynamicFrame в Apache Spark
DataFrame , чтобы вы могли применить преобразования, которые уже существуют в Apache Spark
SQL:
orgs = orgs.drop_fields (['другие_имя',
'идентификаторы']). rename_field (
'id', 'org_id'). rename_field (
'имя', 'org_name')
orgs.toDF (). показать ()
Ниже показан результат:
+ -------------- + -------------------- + ------------- ------- + -------------------- + ----- + ----------- + --- ----------------- +
| классификация | org_id | org_name | ссылки | места | тип | изображение |
+ -------------- + -------------------- + ------------- ------- + -------------------- + ----- + ----------- + --- ----------------- +
| вечеринка | party / al | AL | null | null | null | null |
| вечеринка | партия / демократ | Демократ | [[сайт, http: //... | null | null | https: //upload.wi ... |
| партия | партия / демократия ... | Демократ-Либерал | [[сайт, http: // ... | null | null | null |
| законодательный орган | d56acebe-8fdc-47b ... | Палата представителей ... | null | 435 | нижняя палата | null |
| вечеринка | партия / независимая | Независимый | null | null | null | null |
| party | party / new_progres ... | вечеринка | party / new_progres ... | Новый прогрессивный | [[сайт, http: // ... | null | null | https: // загрузить.с ... |
| вечеринка | вечеринка / популярный_дем ... | Народный демократ | [[сайт, http: // ... | null | null | null |
| вечеринка | партийная / республиканская | Республиканский | [[сайт, http: // ... | null | null | https: //upload.wi ... |
| партия | партия / республиканская -... | республиканская-консервативная ... | [[сайт, http: // ... | null | null | null |
| вечеринка | партия / демократ | Демократ | [[сайт, http: // ... | null | null | https: //upload.wi ... |
| вечеринка | партия / независимая | Независимый | null | null | null | null |
| вечеринка | партийная / республиканская | Республиканский | [[сайт, http: //... | null | null | https: //upload.wi ... |
| законодательный орган | 8fa6c3d2-71dc-478 ... | Сенат | null | 100 | верхняя палата | null |
+ -------------- + -------------------- + ------------- ------- + -------------------- + ----- + ----------- + --- ----------------- +
Введите следующее, чтобы просмотреть организаций , которые появляются в
членства :
членство.select_fields (['идентификатор_организации']). toDF (). independent (). show ()
Ниже показан результат:
+ -------------------- +
| идентификатор_организации |
+ -------------------- +
| d56acebe-8fdc-47b ... |
| 8fa6c3d2-71dc-478 ... |
+ -------------------- +
Шаг 5: Поместите
Все вместе
Теперь используйте AWS Glue, чтобы объединить эти реляционные таблицы и создать одну полную таблицу истории.
из
Законодатель членства и их соответствующие организации .
Сначала присоединитесь к
лицамичленстванаidи
person_id.Затем объедините результат с
orgsнаorg_idи
идентификатор_организации.Затем удалите избыточные поля,
person_idи
org_id.
Вы можете выполнить все эти операции в одной (расширенной) строке кода:
l_history = Присоединяйтесь.применить (организации,
Join.apply (люди, членство, 'id', 'person_id'),
'org_id', 'organization_id'). drop_fields (['person_id', 'org_id'])
print "Count:", l_history.count ()
l_history.printSchema ()
Результат выглядит следующим образом:
Количество: 10439
корень
| - роль: строка
| - места: int
| - org_name: строка
| - ссылки: массив
| | - элемент: структура
| | | - примечание: строка
| | | - url: строка
| - тип: строка
| - sort_name: строка
| - area_id: строка
| - изображения: массив
| | - элемент: структура
| | | - url: строка
| - on_behalf_of_id: строка
| - other_names: массив
| | - элемент: структура
| | | - примечание: строка
| | | - имя: строка
| | | - lang: строка
| - contact_details: массив
| | - элемент: структура
| | | - тип: строка
| | | - значение: строка
| - имя: строка
| - Birth_date: строка
| - идентификатор_организации: строка
| - пол: строка
| - классификация: строка
| - death_date: строка
| - законодательный_период_id: строка
| - идентификаторы: массив
| | - элемент: структура
| | | - схема: строка
| | | - идентификатор: строка
| - изображение: строка
| - given_name: строка
| - family_name: строка
| - id: строка
| - start_date: строка
| - end_date: строка
Теперь у вас есть итоговая таблица, которую вы можете использовать для анализа.Вы можете записать это в
а
компактный, эффективный формат для аналитики, а именно Parquet, который позволяет запускать SQL
в AWS Glue, Amazon Athena или Amazon Redshift Spectrum.
Следующий вызов записывает таблицу из нескольких файлов в
поддержка быстрого параллельного чтения при дальнейшем анализе:
glueContext.write_dynamic_frame.from_options (frame = l_history,
connection_type = "s3",
connection_options = {"путь": "s3: // цель-образца-клея / каталог-вывода / законодательная_история"},
format = "паркет")
Чтобы поместить все данные истории в один файл, вы должны преобразовать его во фрейм данных,
переразбейте его и запишите:
s_history = l_history.toDF (). repartition (1)
s_history.write.parquet ('s3: // glue-sample-target / output-dir / законодательный_сингл')
Или, если вы хотите разделить его на Сенат и Палату представителей:
l_history.toDF () .write.parquet ('s3: // glue-sample-target / output-dir / законодатель_часть',
partitionBy = ['org_name'])
Шаг 6: Запись
данные в реляционные базы данных
AWS Glue упрощает запись данных в реляционные базы данных, такие как Amazon Redshift,
даже с
полуструктурированные данные.Он предлагает преобразование relationalize , которое сглаживает
DynamicFrames независимо от того, насколько сложными могут быть объекты в кадре.
Использование l_history
DynamicFrame в этом примере передайте имя корневой таблицы
( hist_root ) и временный рабочий путь к реляционализировать .Этот
возвращает DynamicFrameCollection . Затем вы можете перечислить имена
DynamicFrames в этой коллекции:
dfc = l_history.relationalize ("hist_root", "s3: // glue-sample-target / temp-dir /")
dfc.keys ()
Ниже приведен результат вызова ключей :
[u'hist_root ', u'hist_root_contact_details', u'hist_root_links ',
u'hist_root_other_names ', u'hist_root_images', u'hist_root_identifiers ']
Relationalize разбил таблицу истории на шесть новых таблиц: корневая таблица
который содержит запись для каждого объекта в DynamicFrame и вспомогательные таблицы
для массивов.Обработка массивов в реляционных базах данных часто неоптимальна, особенно
в виде
эти массивы становятся большими. Разделение массивов на разные таблицы делает запросы
идти
намного быстрее.
Затем посмотрите на разделение, проверив contact_details :
l_history.select_fields ('contact_details'). printSchema ()
dfc.select ('hist_root_contact_details'). toDF (). where ("id = 10 or id = 75"). orderBy (['id', 'index']). show ()
Ниже приведены выходные данные вызова show :
корень
| - contact_details: массив
| | - элемент: структура
| | | - тип: строка
| | | - значение: строка
+ --- + ----- + ------------------------ + -------------- ----------- +
| id | index | contact_details.val.type | contact_details.val.value |
+ --- + ----- + ------------------------ + -------------- ----------- +
| 10 | 0 | факс | |
| 10 | 1 | | 202-225-1314 |
| 10 | 2 | телефон | |
| 10 | 3 | | 202-225-3772 |
| 10 | 4 | twitter | |
| 10 | 5 | | MikeRossUpdates |
| 75 | 0 | факс | |
| 75 | 1 | | 202-225-7856 |
| 75 | 2 | телефон | |
| 75 | 3 | | 202-225-2711 |
| 75 | 4 | twitter | |
| 75 | 5 | | SenCapito |
+ --- + ----- + ------------------------ + -------------- ----------- +
Поле contact_details было массивом структур в исходном
DynamicFrame .Каждый элемент этих массивов представляет собой отдельную строку вспомогательного
таблица, проиндексированная индексом . id — это внешний ключ в
hist_root таблица с ключом contact_details :
dfc.select ('hist_root'). toDF (). где (
«contact_details = 10 или contact_details = 75»).Выбрать(
['id', 'given_name', 'family_name', 'contact_details']). show ()
Это результат:
+ -------------------- + ---------- + ----------- + ----- ---------- +
| id | given_name | family_name | contact_details |
+ -------------------- + ---------- + ----------- + ----- ---------- +
| f4fc30ee-7b42-432 ... | Майк | Росс | 10 |
| e3c60f34-7d1b-4c0... | Шелли | Капитон | 75 |
+ -------------------- + ---------- + ----------- + ----- ---------- +
Обратите внимание, что в этих командах toDF () , а затем , где выражение
используются для фильтрации строк, которые вы хотите увидеть.
Итак, объединение таблицы hist_root со вспомогательными таблицами позволяет выполнять
следующий:
У вас уже настроено соединение с именем redshift3 .Для получения информации о
о том, как создать собственное подключение, см. в разделе «Определение подключений в каталоге данных AWS Glue».
Затем запишите эту коллекцию в Amazon Redshift, прокрутив DynamicFrames
один за раз:
для df_name в dfc.ключи ():
m_df = dfc.select (имя_дф)
print "Запись в таблицу Redshift:", df_name
glueContext.write_dynamic_frame.from_jdbc_conf (frame = m_df,
catalog_connection = "красное смещение3",
connection_options = {"dbtable": df_name, "database": "testdb"},
redshift_tmp_dir = "s3: // glue-sample-target / temp-dir /")
Свойство dbtable — это имя таблицы JDBC.Для хранилищ данных JDBC, поддерживающих схемы
в базе данных укажите schema.table-name . Если схема не указана, то используется «общедоступная» схема по умолчанию.
Для получения дополнительной информации см. Типы подключений и параметры для ETL в
AWS Glue.
Вот как выглядят таблицы в Amazon Redshift.(Вы подключились к Amazon Redshift
через psql.)
testdb = # \ d
Список отношений
схема | имя | тип | владелец
-------- + --------------------------- + ------- + ----- ------
общественный | hist_root | стол | test_user
общественный | hist_root_contact_details | стол | test_user
общественный | hist_root_identifiers | стол | test_user
общественный | hist_root_images | стол | test_user
общественный | hist_root_links | стол | test_user
общественный | hist_root_other_names | стол | test_user
(6 рядов)
testdb = # \ d hist_root_contact_details
Таблица "паблик".hist_root_contact_details "
Колонка | Тип | Модификаторы
--------------------------- + ---------------------- ---- + -----------
id | bigint |
индекс | целое |
contact_details.val.type | различный характер (65535) |
contact_details.val.value | различный характер (65535) |
testdb = # \ d hist_root
Таблица "public.hist_root"
Колонка | Тип | Модификаторы
----------------------- + -------------------------- + -----------
роль | различный характер (65535) |
сиденья | целое |
org_name | различный характер (65535) |
ссылки | bigint |
тип | различный характер (65535) |
sort_name | различный характер (65535) |
area_id | различный характер (65535) |
изображения | bigint |
on_behalf_of_id | различный характер (65535) |
other_names | bigint |
дата рождения | различный характер (65535) |
имя | различный характер (65535) |
идентификатор_организации | различный характер (65535) |
пол | различный характер (65535) |
классификация | различный характер (65535) |
законодательный_период_ид | различный характер (65535) |
идентификаторы | bigint |
given_name | различный характер (65535) |
изображение | различный характер (65535) |
family_name | различный характер (65535) |
id | различный характер (65535) |
death_date | различный характер (65535) |
start_date | различный характер (65535) |
contact_details | bigint |
end_date | различный характер (65535) |
Теперь вы можете запрашивать эти таблицы с помощью SQL в Amazon Redshift:
testdb = # выберите * из hist_root_contact_details, где id = 10 или id = 75, упорядочить по идентификатору, индексу;
Результат:
id | индекс | Контактная информация.val.type | contact_details.val.value
--- + ------- + -------------------------- + ----------- ----------------
10 | 0 | факс | 202-224-6020
10 | 1 | телефон | 202-224-3744
10 | 2 | twitter | ЧакГрэссли
75 | 0 | факс | 202-224-4680
75 | 1 | телефон | 202-224-4642
75 | 2 | twitter | СенДжекРид
(6 рядов)
Заключение
В целом AWS Glue очень гибкий.Он позволяет вам с помощью нескольких строк кода:
какие
обычно на написание уходит несколько дней. Вы можете найти все сценарии ETL от источника к цели
в
Файл Python join_and_relationalize.py в примерах AWS Glue на GitHub.
Паркетная доска HARO Engineered Wood Паркет Дубовая паркетная доска Loop 4V
Паркетная доска HARO Parkettmanufaktur Дубовая паркетная доска Loop 4V
Если вы ищете элегантный структурированный паркет для жилых или подсобных помещений, обратите внимание на этот качественный паркет в декоре дуба HARO.Подчеркивает характеристики древесины дуба на основе паркетной доски Loop. Бежево-коричневый цвет делает комнаты светлыми и уютными. Кроме того, у этого паркета убедительны свойства укладки и использования. Узнайте больше о высококачественном паркете HARO parkettmanufaktur Oak Parquet Flooring Loop 4V.
Структурированный паркет с элегантным декором из дуба
Паркет HARO сочетает в себе естественные характеристики древесины дуба со структурой паркетной панели Loop. К этому добавляется элегантный бежево-коричневый цвет, который делает каждую комнату яркой, уютной и уютной.Дубовый паркет подходит к разным стилям интерьера.
Простая и разнообразная укладка дубового паркета HARO
Этот паркет с декором из дуба из серии HARO Parquet Manufacture отличается превосходными укладывающими свойствами. Квадратные доски соединяются шпунтом и пазом, а затем их можно склеить по всей поверхности с помощью эластичного клея. Благодаря круговой фаске создается гармоничная общая картина. Доски имеют длину 65 сантиметров, ширину 65 сантиметров и толщину 18 миллиметров.В каждой упаковке вы получите две доски на площадь укладки 0,85 кв.
Современный дубовый паркет с износостойкими свойствами
Дубовый паркет из популярной серии HARO Parquet Manufacture отличается превосходным качеством материала и изготовлением. Доски имеют прочную трехслойную конструкцию, усиленную центральным слоем стержней из массива дерева. Высокая стабильность размеров сопровождается эффективной звукоизоляцией и приятным комфортом при ходьбе. Поверхность досок имеет 3.Слой износа толщиной 5 миллиметров, который можно шлифовать несколько раз. Кроме того, поверхность смазывается маслом, поэтому она устойчива к истиранию, царапинам, разводам, пятнам и механическим повреждениям. На бежево-коричневый дубовый паркет производитель дает 30-летнюю гарантию на установку в жилой зоне. Вот обзор характеристик использования современного дубового паркета из серии HARO Parquet Manufacture:
- бежевый дубовый декор
- Паркетная доска Петля
- пропитанная маслом и истираемая поверхность
- 3.Толщина слоя износа 5 мм.
- Центральная вставка из массива дерева
- Гарантия 30 лет
Классический дубовый паркет бежево-коричневого цвета в круговой паркетной доске
Этот классический дубовый паркет гармонично и элегантно оформлен в жилых и хозяйственных помещениях. Фактурная паркетная панель и бежево-коричневый цвет придали каждой комнате светлый, уютный и домашний характер. Кроме того, этот паркет имеет отличные укладочные и эксплуатационные свойства. Вы тоже можете украсить свой дом высококачественным дубовым паркетом из серии HARO Parquet Manufacture.
Пример использования Uber: выбор правильного формата файла HDFS для ваших заданий Apache Spark
В рамках наших усилий по созданию лучшего пользовательского опыта на нашей платформе члены нашей группы сбора данных карт используют специальное мобильное приложение для сбора изображений и связанных с ними метаданных для улучшения наших карт. Например, наша команда снимает изображения уличных знаков, чтобы повысить эффективность и качество данных наших карт, чтобы облегчить поездку как для гонщиков, так и для водителей-партнеров, а также фотографирует продукты питания, которые будут отображаться в Приложение Uber Eats.Затем мы обрабатываем изображения и метаданные с помощью серии заданий Apache Spark и сохраняем результаты в нашем экземпляре распределенной файловой системы Hadoop (HDFS).
Для одного из крупнейших проектов группы сбора данных Maps потребовалось получить и обработать более восьми миллиардов изображений. К изображениям необходимо было получить эффективный доступ для последующих заданий Apache Spark, а также для произвольного доступа операторов, ответственных за редактирование карт. Хотя выбор дизайна, который мы сделали для нашей архитектуры Apache Spark, потребовал от нас обработки миллиардов изображений, полученный шаблон также был применен к проектам со значительно меньшим масштабом, состоящим из тысяч изображений.
Apache Spark поддерживает несколько форматов файлов, которые позволяют хранить несколько записей в одном файле. У каждого формата файла есть свои преимущества и недостатки.
В этой статье мы опишем форматы файлов, которые команда по сбору данных карт использует для обработки больших объемов изображений и метаданных, чтобы оптимизировать работу для последующих потребителей. Мы надеемся, что вы найдете эти выводы полезными для ваших собственных нужд в области анализа данных.
Использование Apache Spark с HDFS
Изображения и метаданные собираются с помощью специального мобильного приложения, разработанного Uber.После сбора данных мобильное приложение загружает данные в облачное хранилище. Изображения и метаданные загружаются из облачного хранилища в центры обработки данных Uber, а затем обрабатываются:
- Принятие : Помещает необработанные данные в центр обработки данных, чтобы их можно было обрабатывать параллельно.
- Обработка / преобразование : серия шагов, которые распаковывают необработанные данные и выполняют обработку для преобразования данных в полезную информацию для последующих потребителей.
Рисунок 1.Мы загружаем изображения и метаданные изображений в центры обработки данных Uber, а затем используем Apache Spark для обработки изображений и метаданных.
Для каждого типа вывода используются следующие форматы файлов.
- Полученные данные : файлы SequenceFiles обеспечивают эффективную запись для данных больших двоичных объектов.
- Промежуточные данные : Avro предлагает широкую поддержку схем и более эффективную запись, чем Parquet, особенно для данных BLOB-объектов.
- Окончательный результат : комбинация файлов Parquet, Avro и JSON
- Метаданные изображений : Parquet оптимизирован для эффективных запросов и фильтрации.
- Изображение : Avro лучше оптимизирован для двоичных данных, чем Parquet, и поддерживает произвольный доступ для эффективных объединений.
- Агрегированные метаданные : JSON эффективен для небольших количеств записей, распределенных по большому количеству файлов, и его легче отлаживать, чем двоичные форматы файлов.
У каждого формата файла есть свои плюсы и минусы, и каждый тип вывода должен поддерживать уникальный набор сценариев использования. Для каждого типа вывода мы выбрали формат файла, который максимизирует плюсы и минимизирует минусы.В следующих разделах мы объясняем, почему каждый формат файла был выбран для каждого типа формата.
Полученные данные
Прием данных — это процесс, с помощью которого данные, записанные разработанным Uber приложением для мобильных телефонов, эффективно перемещаются в центр обработки данных для дальнейшей обработки. Ingest читает из внешнего источника и записывает данные в HDFS, чтобы файлы можно было эффективно обрабатывать с помощью заданий Spark. Хранение небольшого количества больших файлов предпочтительнее большого количества маленьких файлов в HDFS, поскольку оно потребляет меньше ресурсов памяти на NameNodes и повышает эффективность заданий Spark, ответственных за обработку файлов.(Если вы хотите узнать больше по этой теме, мы рекомендуем прочитать эту статью в блоге Cloudera Engineering).
Во время приема содержимое файлов не изменяется, поэтому дополнительная обработка и преобразования могут выполняться параллельно через Spark. Задания Spark, отвечающие за обработку и преобразования, читают данные целиком и практически не фильтруют. Поэтому используется простой формат файла, который обеспечивает оптимальную производительность записи и не имеет накладных расходов, связанных с форматами файлов, ориентированными на схему, такими как Apache Avro и Apache Parquet.
Каждый экземпляр загрузки записывает файлы в один файл последовательности HDFS, в результате чего получается несколько больших файлов, что оптимально для HDFS. SequenceFile — это плоский файл, состоящий из двоичных пар ключ / значение. API позволяет хранить данные либо в двоичном ключе, либо в другом типе данных, таком как строка или целое число. В случае загрузки ключ представляет собой строку, содержащую полный путь к файлу, а значение представляет собой двоичный массив, содержащий содержимое загруженного файла.
Промежуточные данные
После приема данных серия заданий Spark преобразуется и выполняет дополнительную обработку данных.Каждое задание Spark в серии записывает промежуточные данные. Промежуточные данные, созданные предыдущей задачей, чаще всего считываются целиком и не фильтруются ни по столбцам, ни по строкам. Для этого типа промежуточных данных мы обычно используем формат файла Avro.
Формат файла
Spark по умолчанию — Parquet. Parquet имеет ряд преимуществ, которые повышают производительность запросов и фильтрации данных. Однако эти преимущества требуют предварительной оплаты при записи файлов. Parquet — это формат файла на основе столбцов, что означает, что все значения для данного столбца по всем строкам, хранящимся в физическом файле (также известном как блок), группируются вместе перед записью на диск.Таким образом, все записи должны быть сохранены и перегруппированы в памяти перед записью блока. Напротив, файл Avro — это формат файла на основе записей, который позволяет более эффективно передавать записи на диск. (На веб-сайте Parquet есть серия записанных презентаций, в которых дается более подробное объяснение столбчатых форматов файлов.)
Из-за меньших накладных расходов на запись файлы Avro обычно используются для хранения промежуточных данных, когда:
- Данные записываются один раз и читаются один раз.
- Считыватель не фильтрует данные.
- Считыватель последовательно считывает данные.
Окончательный результат
Конечным выходом являются обработанные данные, к которым обращаются несколько нижестоящих потребителей. У каждого потребителя есть уникальные требования, которые часто решаются путем запроса и фильтрации данных. Например, потребитель может выполнить геопространственный запрос изображений определенного типа. Окончательный результат делится на три категории:
- Метаданные изображения : данные об изображении, например, место, из которого они были сняты.
- Изображение : изображения, полученные датчиком.
- Агрегированные данные : высокоуровневые данные о наборе изображений, такие как версия программного обеспечения, используемого для обработки изображений, или агрегированные показатели выходных данных.
Метаданные изображения
В отличие от промежуточных данных, метаданные изображений читаются несколько раз и часто фильтруются и запрашиваются. Данные хранятся в Parquet, потому что преимущества значительно перевешивают дополнительные накладные расходы на запись.Ниже приведены результаты двух тестов производительности, в которых было запрошено около пяти миллионов записей.
Первый запрос — это простой запрос ограничивающей рамки по широте и долготе изображения, который возвращает примерно 250 000 записей. С точки зрения нижележащего потребителя запрос Parquet выполняется почти в три раза быстрее. Однако реальное влияние оказывается на базовую инфраструктуру.
Наибольшее улучшение — это ввод-вывод, необходимый для запросов, где Parquet потребляет 7.5 процентов операций ввода-вывода, необходимых для запроса Avro. Формат файла Parquet хранит статистику, которая значительно сокращает объем считываемых данных.
| Ресурс | Авро | Паркет | Улучшение |
| Время стены (сек) | 20,76 | 7,17 | 290% |
| Время ядра (мин) | 24.80 | 1,28 | 1 938% |
| Прочтений (МБ) | 24 678.4 | 1848,5 | 1,335% |
Второй запрос — это сравнение строк, которое возвращает примерно 40 000 записей. И снова запрос к файлам Parquet работал значительно лучше, чем к файлам Avro. Запрос Parquet выполняется в два раза быстрее и требует 1,5% операций ввода-вывода по сравнению с аналогичным запросом Avro.
| Ресурс | Авро | Паркет | Улучшение |
| Время стены (сек) | 18.48 | 6,0 | 308% |
| Время ядра (мин) | 1670,00 | 50,76 | 3 289% |
| Прочтений (МБ) | 24 678,4 | 376,6 | 6,552% |
Изображения
Parquet не оптимален для хранения больших двоичных данных, таких как изображения, поскольку это ресурсоемкий процесс упорядочивания больших двоичных данных в столбчатом формате. С другой стороны, Avro неплохо работает для хранения изображений.Однако, как обсуждалось в предыдущем разделе, Avro не оптимален для запросов.
Для поддержки запросов к файлам Parquet метаданных изображений добавляются два столбца, которые служат внешним ключом к изображениям. Это позволяет клиентам запрашивать изображения через метаданные.
Чтобы понять, как реализована перекрестная ссылка, необходимо учесть две ключевые детали:
- Файл части : Spark подразделяет данные на разделы, и когда данные записываются в Avro, каждый раздел записывается в отдельный файл части.
- Смещение записи: API Avro поддерживает возможность получения смещения в файл, где хранится конкретная запись. Учитывая смещение, Avro API может эффективно искать местоположение файла и читать запись. Эта функция доступна через собственный API Avro, а не через API оболочки Spark для Avro.
Два столбца, добавленные к метаданным изображения, используемые в качестве перекрестной ссылки на изображение, — это имя файла детали, в котором хранится запись изображения, и смещение файла записи в файле детали.Поскольку API оболочки Spark для файлов Avro не раскрывает смещение записи, для записи изображений необходимо использовать собственный API Avro.
Изображения записываются на карте Spark. Реализация будет зависеть от версии Spark и от того, используются ли API DataFrame или Resilient Distributed Dataset, но концепция остается той же. Выполните метод для каждого раздела с помощью вызова карты Spark и используйте собственный API Avro для записи отдельного файла детали, содержащего все изображения, содержащиеся в разделе.Общие шаги следующие:
- Прочитать файл последовательности захвата.
- Сопоставьте каждый раздел полученного файла SequenceFile и передайте идентификатор раздела в функцию сопоставления. Для RDD вызовите rdd.mapPartitionsWithIndex (). Для DataFrame вы можете получить идентификатор раздела с помощью spark_partition_id (), сгруппировать по идентификатору раздела с помощью df.groupByKey (), а затем вызвать df.flatMapGroups ().
- В функции карты выполните следующие действия:
- Создайте стандартный Avro Writer (не Spark) и включите идентификатор раздела в имя файла.
- Перебирать каждую запись полученного файла SequenceFile и записывать записи в файл Avro.
- Вызов DataFileWriter.sync () в Avro API. Это сбросит запись на диск и вернет смещение записи.
- Передайте имя файла и смещение записи через возвращаемое значение функции карты вместе с любыми дополнительными метаданными, которые вы хотите извлечь из изображения.
- Сохраните полученный DataFrame или RDD в формате Parquet.
Результат — Avro и сопутствующий файл Parquet.Файл Avro содержит изображения, а сопутствующий файл Parquet содержит путь к файлу Avro и смещение записи для эффективного поиска файла Avro для данной записи изображения. Общий шаблон для запроса и последующего чтения записей изображений:
- Запросить файлы Parquet.
- Включите в результаты путь к файлу и смещение.
- Необязательно перераспределите результаты, чтобы настроить степень параллелизма для чтения записей изображений.
- Сопоставьте каждый раздел результатов запроса.
- В функции карты выполните следующие действия:
- Создайте стандартный считыватель Avro для файла детали Avro, который содержит запись изображения.
- Вызовите DataFileReader.seek (long), чтобы прочитать запись изображения по указанному смещению.
Сводные данные
В дополнение к метаданным для данного изображения нам полезно хранить агрегированные метаданные обо всем наборе изображений, хранящихся в данной паре файлов Avro и Parquet. В случае использования Uber примеры агрегированных метаданных включают:
- Версия конвейера, используемая для обработки заданного набора изображений.Если в конвейере обнаруживается ошибка, эти данные используются для эффективной идентификации изображений, которые необходимо повторно обработать.
- Географическая область, в которой были собраны изображения. Это позволяет клиентам определять, какие пары файлов Avro и Parquet включить в геопространственный поиск.
Агрегированные данные хранятся в файлах JSON по следующим причинам:
- Возможность отладки : поскольку файлы JSON представляют собой форматированный текст и обычно содержат небольшое количество записей, их можно легко отобразить без кода или специальных инструментов.
- «Достаточно эффективно» Считывает : во многих случаях файл JSON будет содержать единственную запись для данной пары Avro и Parquet. И Parquet, и Avro имеют накладные расходы, потому что оба формата файлов содержат информацию заголовка. JSON не имеет этих накладных расходов из-за отсутствия в форматах информации заголовка.
- Ссылочная целостность : Альтернативой может быть хранение агрегированных записей в базе данных. Однако если файлы JSON, Avro и Parquet для данного набора изображений хранятся в единственном родительском каталоге, то изображения, метаданные изображений и агрегированные метаданные можно заархивировать, переместив родительский каталог с помощью одной атомарной операции HDFS.
Основные выводы
Формат файла по умолчанию для Spark — Parquet, но, как мы обсуждали выше, есть варианты использования, где лучше подходят другие форматы, в том числе:
- SequenceFiles: двоичная пара ключ / значение, которая является хорошим выбором для хранилища больших двоичных объектов, когда не требуются накладные расходы на поддержку расширенной схемы
- Parquet: поддерживает эффективные запросы, строго типизированные схемы и имеет ряд других преимуществ, не описанных в этой статье.
- Avro: идеально подходит для больших двоичных данных или когда последующие потребители читают записи целиком, а также поддерживает произвольный доступ к записям.Предоставляет возможность определять строго типизированную схему.
- JSON: идеально, когда записи хранятся в нескольких небольших файлах
Выбрав оптимальный формат файла HDFS для ваших заданий Spark, вы можете гарантировать, что они будут эффективно использовать ресурсы центра обработки данных и наилучшим образом удовлетворить потребности последующих потребителей.
Если вас интересует работа над крупномасштабными задачами обработки данных или технологиями компьютерного зрения, подумайте о том, чтобы подать заявку на роль в нашей инженерной команде в Боулдере, штат Колорадо!
Data Engineers будут ненавидеть вас — один странный трюк для исправления ваших схем Pyspark
Я поделюсь с вами отрывком, который избавил меня от многих страданий, связанных с моей работой с фреймами данных pyspark.Это специфично для pysparks. Здесь не на что смотреть, если вы не пользователь pyspark. Первые два раздела состоят из того, что я жалуюсь на схемы, а оставшиеся два предлагают то, что я считаю изящным способом создания схемы из словаря (или кадра данных из набора словаря).
Хорошие, плохие и уродливые фреймы данных
Dataframes в pyspark одновременно довольно хороши, а вид полностью сломан.
- они применяют схему
- , вы можете запускать SQL-запросы к ним
- быстрее, чем rdd
- намного меньше, чем rdd при хранении в формате паркета
С другой стороны:
- соединение фрейма данных иногда дает неправильные результаты
- внешнее соединение pyspark dataframe действует как внутреннее соединение
- при кэшировании с
df.cache () кадры данныхиногда начинают выдавать ключ, не найденный, и драйвер Spark умирает. В других случаях задача выполняется успешно, но основной rdd оказывается поврежденным (значения полей меняются). - на самом деле не ошибка фрейма данных, но связанная с этим — паркет не читается человеком, что отстой — не может легко проверить ваши сохраненные фреймы данных
Но самая большая проблема — это преобразование данных. Он отлично работает с надуманными примерами из руководств. Но я не работаю с плоскими наборами данных в виде таблиц SQL.Или, если да, они уже есть в какой-то базе данных SQL. Когда я использую Spark, я использую его для работы с беспорядочными многослойными json-подобными объектами. Если бы мне пришлось создать UDF и набрать гигантскую схему для каждого преобразования, которое я хочу выполнить с набором данных, я бы весь день больше ничего не делал, я даже не шучу. UDF в pyspark в лучшем случае неудобны, но в моем типичном сценарии использования они непригодны. Возьмем, к примеру, эту относительно маленькую запись:
1 2 3 4 5 6 7 8 9 10 11 12 | |
правильная схема для этого создается следующим образом:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
И это то, что мне приходилось набирать каждый раз, когда мне нужен udf для возврата такой записи — что может быть много раз за одну искру.
Dataframe из rdd — как это бывает
По этим причинам (+ устаревшие выходные данные заданий json из дней hadoop) я обнаружил, что переключаюсь между кадрами данных и rdds. Прочтите некоторый набор данных JSON в rdd, преобразуйте его, соедините с другим, преобразуйте еще несколько, преобразуйте в фрейм данных и сохраните как паркет. Или считайте некоторые файлы паркета в фрейм данных, конвертируйте в rdd, сделайте с ним что-нибудь, конвертируйте обратно в фрейм данных и снова сохраните как паркет. Этот рабочий процесс не так уж и плох — я извлекаю лучшее из обоих миров, используя rdds и dataframe только для тех вещей, в которых они хороши.Как перейти от фрейма данных к целому ряду словарей? Эта часть проста:
1 | |
Проблематично другое направление. Вы могли подумать, что метод toDF () rdd справится с этой задачей, но нет, он не работает.
фактически возвращает фрейм данных со следующей схемой ( df.printSchema () ):
1 2 3 4 5 6 7 8 | |
Он интерпретировал внутренний словарь как карту из логического вместо структуры и молча отбросил все поля в нем, которые не являются логическими.Но в любом случае этот метод устарел. Предпочтительный официальный способ создания фрейма данных — это rdd из объектов строки . Так что давай сделаем это.
1 2 3 4 | |
печатает ту же схему, что и предыдущий метод.
В дополнение к этому, оба этих метода полностью завершатся ошибкой, если невозможно определить тип какого-либо поля, потому что все значения оказываются нулевыми при каком-либо запуске задания.
Кроме того, как ни странно, на мой взгляд, порядок столбцов в фрейме данных имеет значение, а порядок ключей — нет. Так что, если у вас есть уже существующая схема, и вы попытаетесь преобразовать в нее ряд диктовок, у вас будут плохие времена.
Как должно быть
Без лишних слов, вот как я сейчас создаю свои фреймы данных:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Это не прерывается случайным образом, не отбрасывает поля и имеет правильную схему.И мне не нужно было вводить какой-либо из этого StructType ([StructField (... чепуха, просто обычный литерал Python, который я получил, запустив
В качестве дополнительного бонуса теперь этот прототип заметно отображается в верхней части моего файла задания, и я могу сказать, как выглядит результат задания, без необходимости декодировать файлы паркета. Код самодокументирования FTW!
Как добраться
А вот как это делается. Сначала нам нужно реализовать наш собственный вывод схемы — как он должен работать:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Используя это, теперь мы можем указать схему, используя обычный объект Python — больше никаких мерзостей в стиле java. Но это еще не все. Нам также понадобится функция, которая преобразует python dict в объект rRw с правильной схемой. Вы можете подумать, что это должно происходить автоматически, если в dict есть все нужные поля, но никакой порядок полей в строке не имеет значения, поэтому мы должны делать это сами.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 год 22 23 24 25 26 год 27 28 год 29 30 31 год 32 | |
И наконец:
1 2 3 4 5 | |
A ЗА СЦЕНАМИ ПОСМОТРЕТЬ НАШИ ИНЛЮВНЫЕ ПОЛЫ РУКОВОДСТВОМ — PID Floors
25.02.21
Мы хотели рассказать немного о закулисье, где творится волшебство в нашем ультрасовременном здании в Бруклине. Именно здесь мы создаем деревянные полы по индивидуальному заказу и располагаем всеми возможностями по индивидуальному заказу. На этих изображениях наши опытные мастера усердно трудятся над созданием половиц для нашей коллекции InLove, используя те же методы, которые были разработаны и использовались более 300 лет назад, до появления пигментных пятен или красок.Это многоэтапный процесс, и каждый шаг выполняется вручную.
Пятна для пола от пигмента или красителя насыщают древесину цветом. Наши естественные реакционные морилки и процессы копчения древесины сильно отличаются, потому что они химически изменяют физическую структуру древесины на молекулярном уровне для получения желаемого цвета или эффекта.
Для изготовления наших нестандартных цветов требуется около восьми этапов, воспроизводящих настоящий химический процесс выветривания, который дерево испытывает в природе.У нас есть возможность создавать самые разные красивые эффекты и цвета.
Заключительный этап мастерства нашей коллекции inLove — это процесс отделки, наш тщательный и тщательный. Каждая деревянная доска тщательно наносится вручную и затем отдельно сушится на воздухе. Этот процесс может занять несколько недель; время будет зависеть от типа используемой отделки и от того, сколько слоев отделки необходимо для создания желаемого вида. Наша собственная команда по отделке постоянно разрабатывает новые интересные индивидуальные варианты отделки.
Коллекция inLove — это творчество, наука, вдохновение и сотрудничество.
Узнайте больше о том, как проверенные временем методы обработки дерева используются вместе с самыми передовыми технологиями в биохимии для создания нашей коллекции inLove ЗДЕСЬ.
Просмотрите нашу коллекцию InLove ЗДЕСЬ.
Узнайте больше о том, как создать свой собственный настил ЗДЕСЬ.
Узнайте больше о том, где мы делаем нашу коллекцию inLove, Brooklyn Pro Shop & Distribution Center ЗДЕСЬ.
Танец под ритм барабанщика: история петли
Герман Келли — танец под ритм барабанщика
В Нью-Йорке есть «Apache». В Новом Орлеане есть «Триггермен». В Балтиморе есть «Синг-Синг». А в Майами есть «Танцы под ритм барабанщика».
То, что в Майамие называют «booty shake», началось с перерыва с сингла 1978 года Herman Kelly & Life.Он был фаворитом на вечеринках Лютера «Дядя Люк» Кэмпбелла, посвященных Pac Jam, где он вдохновил на танец под названием «Брось член». Щелчки колокольчиков и резкие удары гитары, которые пробудили местных подростков имитировать секс на паркете роликовых катков округа Дейд в середине 80-х, стали одними из самых популярных песен в Miami Bass, начиная с сингла 2 Live Crew, изменившего правила игры, « Бросьте D. »
«Вот откуда всех диких танцев в Майами, танцев попой», — говорит Marvelous J.П., один из основателей группы ди-джеев Luke’s Ghetto Style. Спустя 30 лет после того, как Кэмпбелл основал Luke Skyywalker Records, чтобы выпустить «Throw The D», звук барабанов Келли по-прежнему вдохновляет толпу в Майами.
«Даже сегодня, если вы пойдете на вечеринку для взрослых [в Майами] и включите« Dance to the Drummer’s Beat », все пойдут на пол», — говорит Крис Вонг Вон AKA 2 Live Crew из Fresh Kid Ice. «Вот с чего все началось».
2 Live Crew — Throw the D
Признательность за «Dance to the Drummer’s Beat» проходит далеко на северо-востоке, где его приняли ранние би-бой и хип-хоп ди-джеи Нью-Йорка и исполнили десятки образцов золотой эры. рэп-записи.Но, прежде всего, это запись Майами, сделанная в штаб-квартире Miami Sound Machine Эмилио Эстефана и выпущенная посредством оттиска T.K. Генри Стоуна. Records, типичный лейбл Magic City, на пике популярности как центр дискотеки.
Немногое известно о Келли, авторе, продюсере и исполнителе песни. Хотя он по-прежнему поддерживает музыкальную компанию Afterschool Publishing, «Dance to the Drummer’s Beat» был его единственным хитом. Благодаря Джо Стоуну, который курирует обширный каталог публикаций своего покойного отца Генри, я смог найти Келли по электронной почте.По крайней мере, я думаю, что я разговаривал с Келли: вопросы, отправленные на его адрес, были возвращены с ответами от третьего лица.
«Герман Келли родился в Детройте, — начала Келли. «До прихода в T.K. Records, он был штатным барабанщиком [и] перкуссионистом телешоу [Детройтской радиостанции] WCHB и внештатным студийным музыкантом в районе Детройта, выступая с разными группами в качестве дополнительного барабанщика ». Научившись писать музыку в колледже Генри Форда, Келли перешла в Университет Майами.Перебравшись в тропики, он погрузился в бурно развивающуюся латиноамериканскую музыкальную сцену города, выступая с музыкантами с Кубы и других Карибских островов.
Опираясь на композицию, которую он начал писать, чтобы продемонстрировать свои таланты многомерного перкуссиониста, Келли собрал разнообразных в культурном отношении игроков, чтобы записать «Dance to the Drummer’s Beat» в студии Miami Sound Studio в 1977 году. Праздничная атмосфера, перемежающаяся всевозможными буквальными свистками, «Удар барабанщика» продемонстрировала значительные ударные навыки Келли — его центральным элементом является эффектная игра на бонго, напоминающая работу Багамского конгеро Кинга Эрриссона над песнями «Apache» и «Bongo Rock» группы Incredible Bongo Band.«Easy Going (Noches Eternas)», более приглушенный диско-трек с текстами на испанском и английском языках, был вырезан как B-сайд.
В поисках распространения для сингла Келли, как и многие музыканты из Майами того времени, нашел свой путь к Генри Стоуну и Стиву Алаймо в T.K. Записи. Компания из Хайалиа, популяризировавшая «Майами Саунд» Бетти Райт, Латимор и Литтл Бивер в начале 70-х, стала самым известным диско-лейблом к югу от Нью-Йорка благодаря определяющим жанрам хитам, таким как «Джордж Макрей». Rock Your Baby »и К.C. и группа Sunshine Band «Get Down Tonight». Альбом «Dance to the Drummer’s Beat», приписанный Herman Kelly & Life, был выпущен 12 октября 1978 года дочерней компанией T.K. Electric Cat.
Ударный взрыв! Позже в том же году вышел единственный полноформатный альбом Келли . Альбом был записан между Майами и Бразилией с помощью аранжировок, сделанных исполнительным продюсером Томасом Фундора, кубинским художником и автором песен из Майами. «Томас был бывшим продюсером RCA Brazil», — говорит Келли, объясняя международный масштаб альбома.«Поэтому мы поехали в Бразилию, чтобы закончить запись, и наняли студийных музыкантов RCA, чтобы они сыграли на альбоме».
Herman Kelly & Life — Dance To The Drummer’s Beat (Jim Burgess Remix)
Percussion Explosion! , который представлял собой смесь латиноамериканского соула, юношеских партийных звуков и более традиционного R&B, в конечном итоге не взорвался. Но «Dance to the Drummer’s Beat» набрал обороты в Нью-Йорке благодаря диско-миксу от Джима Берджесса, влиятельного ди-джея-гея, известного своими оперными сетами в таких клубах, как 12 West и Saint.(У него также были связи с Флоридой, поскольку он вырос в Окичоби, примерно в двух часах езды к северо-западу от Майами.) Ремикс Берджесса усилил басы и удвоил продолжительность его подпитываемого бонго перерыва, события, которые, вероятно, способствовали его принятию ранним хипом. -шоп ди-джеев и брейкеров в Бронксе и за его пределами.
В своей книге The Adventures of Grandmaster Flash: My Life, My Beats , Grandmaster Flash называет сингл одним из самых ранних и наиболее важных примеров в волне диско и фанк-записей, которые, казалось, обращались непосредственно к растущей молодежи. движение, выходящее из Нью-Йорка.«Чем веселее становилась музыка с годами, чем ярче становились танцы, и чем ярче становились танцы, тем больше музыка говорила прямо с би-бой», — пишет Флэш. «Герман Келли, Kool & the Gang, Seventh Wonder, эти парни бросали вызов ребятам, чтобы показать, из чего они сделаны».
Pookey Blow — Вставайте (и идите в школу)
В 1981 году части инструментальной части «Drummer’s Beat» были сняты с согласия Келли продюсером из Коннектикута Тони «Mr. Magic »Pearson для песни« Get Up (And Go to School) »детского рэпера Pookey Blow.В примечаниях к обложке The Third Unheard , компиляции ранних жемчужин рэпа Коннектикута, обнаруженных Stones Throw Records в 2004 году, составитель Eothen «Egon» Alapatt предполагает, что это, возможно, был первый легально одобренный сэмпл, с опозданием давая малоизвестный трек новизны Блоу. место в истории хип-хопа.
Спустя четыре года после того, как Блоу отказался от рифм и соло в стиле казу над брейк-битом «Drummer’s Beat», Дабл Ди и Стейнски заметно представили элементы классики Келли в «Уроке 3 (История хип-хоп микса)», последней части своего оригинального брейкбит-коллажа серия «Уроки.Годом позже, в 1986 году, «Dance to the Drummer’s Beat» появилась в третьем томе книги Луи «Breakbeat Lou» Флореса « Ultimate Breaks and Beats ». Включение трека в выпуск очень влиятельной серии сборников гарантировало, что хип-хоп продюсеры по всей стране будут использовать его грувы.
Double Dee & Steinski — Lesson 3 (History of Hip Hop Mix)
Однако ди-джеи Майами, закладывающие основы того, что впоследствии станет басовой музыкой, не нуждались в таком представлении.Наряду с «Boogie Shoes» KC и Sunshine Band, «Let’s Fool Around» генерала Джонсона и «Theme From King Kong» Барри Уайта «Drummer’s Beat» был среди горстки пережитков эпохи диско, популярных в еженедельнике Pac Jam. вечеринка, устроенная ди-джеями в стиле гетто на Sunshine Skateway North в районе Норланд в Майами. К 1985 году, когда Лютер Кэмпбелл впервые пригласил 2 Live Crew, которые тогда базировались на базе ВВС Марш в Риверсайде, штат Калифорния, для выступления в Майами, «Удар барабанщика» стал сиреной для тусовщиков на мероприятиях в стиле гетто, чтобы они «бросили удар». Дик.”
«По сути,« Throw The D »- это то, что они сейчас называют тверком», — объясняет Люк, ссылаясь как на эндшпиль массовой культуры Майами, так и на его карибское происхождение: «Это похоже на грязное вино».
На западно-индийском языке вино — это ритмичное круговое вращение бедер; приглушенное вино — особенно привлекательная женская вариация. Подобно Кэмпбеллу, сыну отца-ямайца и матери-багамца, большая часть публики на Pac Jam и других мероприятиях в стиле гетто были выходцами из Карибского бассейна, знакомы с таким движением и привыкли к нему.
«Это было что-то вроде карнавала, фестиваля перкуссии [из Карибского моря]», — говорит г-н Микс из 2 Live Crew о перерыве «Drummer’s Beat». «Я думаю, что это был розыгрыш рекорда. В Майами вы либо ямайский, либо гаитянский, либо багамского происхождения. Откровенных афроамериканцев действительно не так много ».
Fresh Kid Ice, уроженец Тринидада, ярко вспоминает, как стал свидетелем сцены из «Drummer’s Beat», разыгравшейся в Pac Jam, в его автобиографии 2015 года My Rise 2 Fame : «[Это было] парни, которые метали бедрами вперед и назад и, возможно, сбросить штаны по большому кругу, когда все девушки будут сидеть на корточках, положив руки на колени, выгибая спины и заставляя их трястись.”
Этот опыт произвел достаточно сильное впечатление на Fresh Kid Ice, что он написал текст песни «Throw The D» (вместе с ее возможной стороной B, «Ghetto Bass») во время полета из Майами обратно в Калифорнию, вызвавшего эффект красных глаз. Вернувшись в казармы в Риверсайде, мистер Микс сконструировал бит с помощью драм-машины Roland TR-808, скретчивая сэмплы из «Drummer’s Beat» вместе с отрывками из «Planet Rock» Африки Бамбатаа и The Soulsonic Force и пародией из одного из Комедийные альбомы Руди Рэя Мура Dolemite под названием «Ромео и Джульетта.
Кэмпбелл, который был занят идеей управлять 2 Live Crew после выпуска их первого сингла в Майами, посоветовал группе записать эту песню. Но когда каждый местный лейбл, к которому он обращался, передал его выпуск, он решил заняться выпуском сингла сам, неохотно породив Luke Skyywalker Records, импринт, который будет экспортировать культуру Miami Bass по всей стране и на какое-то время сделать Кэмпбелл одним из самых популярных в мире лейблов. успешные музыкальные руководители за пределами Нью-Йорка и Лос-Анджелеса.
До «Throw The D» лирика 2 Live Crew была строго PG: «The Revelation» можно было даже охарактеризовать как сознательный рэп.После «Throw The D» (который был ошибочно написан «Trow the D» и приписан к «2 Live Croew» на ранних виниловых тиражах) группа будет известна почти исключительно откровенными текстами с рейтингом x. Такое развитие событий мало кто мог предсказать для Fresh Kid Ice, сдержанного медика, который думал, что он может стать врачом после ухода из ВВС, но такой, который определенно подходил Марку «Брат Маркиз» Росс, ловко говорящему знакомому мистера Миккса. который заменил члена-основателя Юрия «Amazing Vee» Виело в группе после «Throw The D.
2 Live Crew переехали в Майами, чтобы присоединиться к Кэмпбеллу, который станет полноправным участником к моменту выхода их дебютного альбома 2 Live Crew Is What We Are позже в 1986 году. Удар во времена записей ответов и «Войн Роксаны», Люк заручился поддержкой своей кузины Анкетт Аллен, чтобы повторить «Throw The D» с женской точки зрения на «Throw the P», в котором более широко использовалось «Throw the P». «Удар барабанщика» и кусочки непристойного комика Лаванды Пейдж, также известного как тетя Эстер из Sanford & Son .
«Throw the D» технически не является первой пластинкой Miami Bass — историки этого жанра обычно цитируют «Bass Rock Express» MC ADE. Но с его использованием устойчивого басового звука 808, вцарапанных сэмплов, явных текстов и в целом гедонистической атмосферы, он стал шаблоном для других последующих записей баса.
Вслед за «Throw the D», «Drummer’s Beat» появился во многих ранних записях Bass, от «Cabbage Patch» Gucci Crew II до «Bust This» MC Shy D, рэпера из Атланты, родившегося в Бронксе, который подписал контракт с Люк в 86-м — а позже сверг империю Кэмпбелла, подав судебный иск из-за невыплаченных гонораров.Когда Басс пронесся по Юго-востоку, новаторские выдающиеся личности, такие как DJ Toomp из Атланты (в «Eliminator» Рахима Мечты) и Мэнни Фреш из Нового Орлеана (в «Freddie’s Back» и «Throw Down», оба с рэпером / напарником Грегори Д.) также взяты из «Drummer’s Beat».
«Это стало похоже на старую запасную песню», — говорит г-н Микс. «Если вы хотите получить хит [бас], вставьте в него гитарные удары« Drummer’s Beat »».
База данных Sampling Whosampled.com каталогизирует 147 случаев использования «Drummer’s Beat», в основном из конца 80-х, хотя, безусловно, всплыло и больше.N.W.A использовала его на «Dope Man» из Straight Outta Compton в 1987 году; Можно услышать, как DJ Jazzy Jeff применяет скретч-трансформер к перерыву на «Live at Union Square», концертной записи 1986 года с Fresh Prince, которая позже была включена в сокращенной форме в LP дуэта 1988 года, He’s the DJ, I Я Рэпер .
Марк 45-й король из Нью-Джерси основал бит для «La Kim Theme» когорты группы Flavor Unit Лакима Шабазза на основе сэмпла «Drummer’s Beat». Мимолетный визг рожка, который открывает оригинал Келли, появляется на протяжении всего произведения Run-DMC «Beats to the Rhyme», затмеваясь только более заметным и узнаваемым отрывком «Nautilus» Боба Джеймса.В 1989 году Body and Soul, недолговечный рэп-дуэт с телеведущим Ди Барнсом, сотрудничал с группой «Trouble Funk» из Вашингтона, округ Колумбия, для быстрого ремейка «Drummer’s Beat», выпущенного на шоу Delicious Vinyl в Лос-Анджелесе. А в Балтиморе, где ди-джеи, такие как Technics, Скотти Б. и Фрэнк Ски, выросший в Майами, определяли современный клубный музыкальный стиль города с его собственным набором фирменных брейков, «Drummer’s Beat» появляется часто, появляясь в таких треках, как 2 Hype Brothers & «Ду-ду-Браун», спродюсированный Фрэнком Лыжами.
Chipman — Peanut Butter Jelly Time
Никто не добывал «Drummer’s Beat» больше, чем DJ Chipman, неутомимый создатель обучающих танцевальных песнопений в Майами.Чипман и его группа Da Bucwheat Boiz впервые использовали перерыв в «U Gotta Go», коллаборации с рэпером Кинсу в 1995 году, основанном на пении, которое завсегдатаи Pac Jam кричали на гостей, нарушающих кодекс поведения клуба. «Drummer’s Beat» появляется во многих других постановках Чипмана, в первую очередь на «Peanut Butter Jelly Time», который стал одним из самых ранних интернет-мемов после того, как в 2001 году его распространила компания Koch Records. Его статус пробного камня в поп-культуре. было подтверждено в эпизоде ноября 2005 года Family Guy , в котором Брайан и Стьюи исполняют серенаду Питеру с титульным пением песни, будучи одетыми в банановые костюмы (однако в сериале вместо оригинального ритма будет использоваться обычная звуковая кровать.) Чипман использовал «Удар барабанщика» с почти идентичным эффектом в «Мороженом и пироге», который позже появился в национальном рекламном ролике сети мороженого Baskin-Robbins.
Герман Келли уехал из Флориды много лет назад, но его фирменный трек до сих пор имеет активную вторую жизнь в Майами. Вы, вероятно, не услышите его на Саут-Бич, но в таких местах, как Либерти-Сити и Опа-Лока, в черных кварталах, густо населенных мобильными звуковыми системами ди-джеев и ориентированными на сообщества пиратскими радиостанциями, пауза «Drummer’s Beat» по-прежнему саундтреки к чему угодно, начиная с матраса. Рекламы безобидных танцевальных номеров на детских днях рождения.Как джай-алай и кубинский кофе, подаваемый через окно, это заведение Майами — редко упоминаемое, но, тем не менее, замечательное своей долговечностью.
